
結論:人材紹介・派遣会社の「書く業務」の2大ボトルネック——媒体別求人票リライトと職務経歴書からの候補者サマリ生成——は、Claude Codeを中心としたPythonパイプラインで大幅に自動化できます。
- 要点1:Google Sheets上の求人マスタデータから、自社サイト・大手求人媒体・SNS向けの3〜4バリエーションを1スクリプトで生成できる。
- 要点2:職務経歴書PDFを構造化JSONに変換し、3行ハイライト+推薦コメントを自動生成することで、CAが候補者の概要把握にかける時間を圧縮できる。
- 要点3:個人情報マスキング・NGワード検査・人間レビューのフローを組み合わせることで、職業安定法上のリスクを管理しながら運用できる。
対象読者:人材紹介・派遣会社のバックエンドエンジニア・情シス・DX担当、RA/CA業務の工数削減を検討しているPM・開発リード。
今日やること:本記事のPDFテキスト抽出サンプルコードをローカルで動かし、手元の職務経歴書(テスト用)でJSONが取れるか確認してみてください。
正直に言うと、人材業界の「書く業務」の多さには毎回驚くんです。
100社以上の研修・導入支援をしてきた中で、人材紹介・派遣会社の方々から特に多かった相談が「求人票を媒体ごとに書き直す作業が地獄」「職務経歴書を読んで概要を掴むのに時間がかかる」というものでした。1つの案件につきIndeed用・自社サイト用・LinkedIn用・SNS用と4パターン書き分けるとなると、文字数・トーン・NGワードがすべて違う。RAが1日に新規求人を5件以上担当していれば、それだけで数時間が消えます。
一方で候補者サマリの生成も似た構造の問題です。CAが職務経歴書を読んで「この方、○○の経験3年、△△スキルあり、マネジメント未経験」とまとめる作業は、慣れれば早いのですが件数が増えるほど積み上がっていく。
この記事では、両方の課題をClaude Codeで実装する具体的な方法を、コードサンプル付きで解説します。「実際にどう書くか」「どこで詰まるか」をエンジニア視点で書きました。架空の成果数値は出しません。その代わり、動くコードと「ここは人間のレビューが絶対に必要」という境界線を明確にします。
人材紹介業の「書く業務」が自動化しにくかった3つの理由
この問題がなぜ今まで解決されなかったのかを整理しておく価値があります。単純に「AIに書かせれば終わり」ではないんです。
理由1: 媒体ごとにルールが複雑すぎる
大手求人媒体A(例:求人ボックス系)はテキストが長文NG・職種名の表記規約がある。LinkedIn英語版が混在する場合は文体が別。SNS採用(X、Instagram)はカジュアルトーンで文字制限あり。自社サイトは比較的自由だが、会社のブランドトーンに合わせる必要がある。これらを人間が媒体ごとに手動で書き分けていました。
理由2: 職務経歴書のフォーマットがバラバラ
転職エージェントを通じて集まる職務経歴書のフォーマットは、リクナビNextのテンプレートを使った人もいれば、Word独自フォーマット、時にはスキャンしたPDFもある。テーブルの位置、見出しの有無、箇条書きか文章かが人によって違う。これをパースして構造化するのが技術的に厄介でした。
理由3: 個人情報の取り扱いで二の足を踏む
職務経歴書には氏名・住所・電話番号・メールアドレスが含まれています。これをそのままクラウドAIに投げることへの社内承認が通りにくかった。また職業安定法上、求職者情報の取り扱いには一定の制約があります。このため「AIを使いたいが法務がOKを出してくれない」という状態が続いていました。
2026年時点では、これら3つをすべて解決できる技術スタックが揃っています。順番に実装していきましょう。
全体アーキテクチャ:2本の柱と個人情報マスキングレイヤー
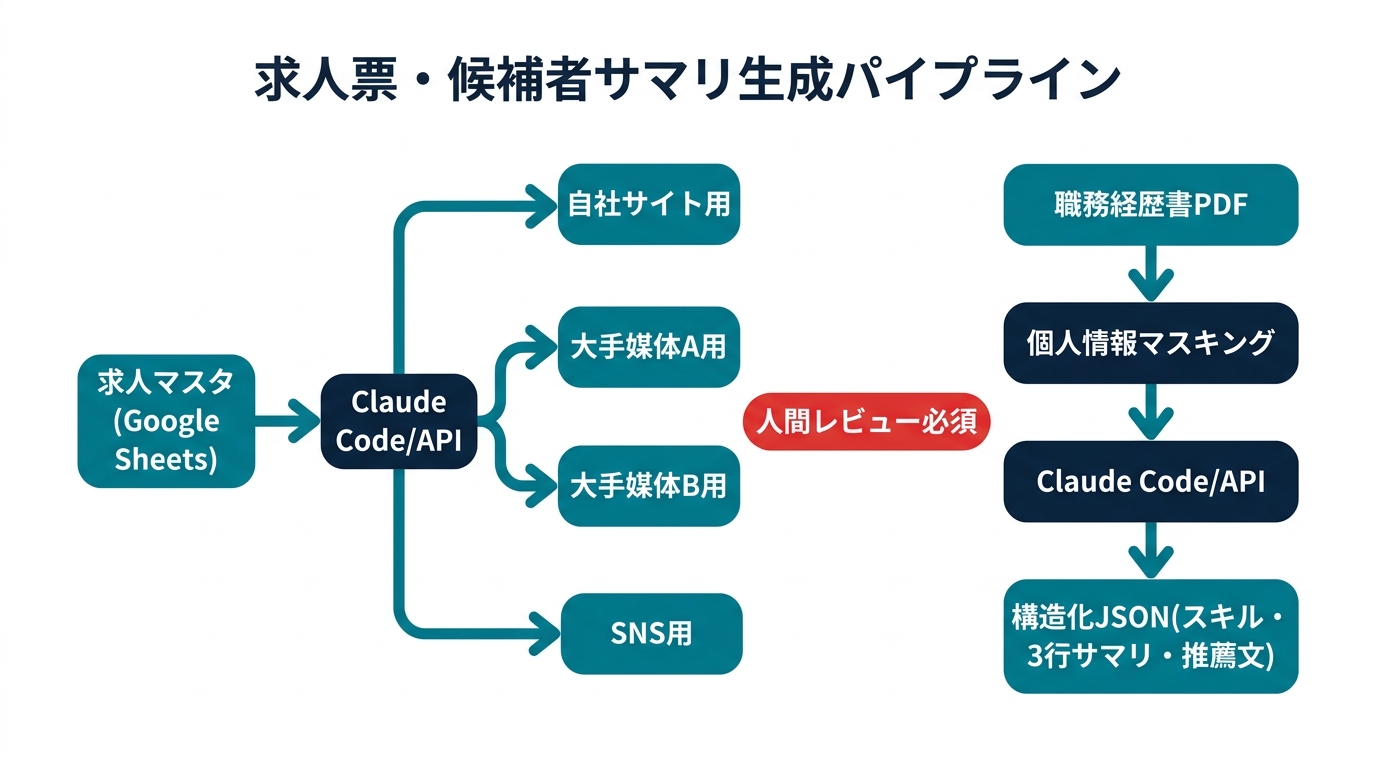
本実装は2本の独立したパイプラインで構成されます。
Pillar 1:求人票媒体別リライトパイプライン
- 入力:Google Sheetsの求人マスタ(職種名・仕事内容・必須スキル・給与・勤務地)
- 処理:Claude APIで媒体別トーン・文字数・NGワード制御付きリライト
- 出力:Google Sheetsの別シートに媒体別テキストを書き戻し
Pillar 2:候補者サマリ生成パイプライン
- 入力:職務経歴書PDF(ローカルファイルパスまたはGCSバケット)
- 処理:pdfplumberでテキスト抽出→個人情報マスキング→Claude APIで構造化JSON+サマリ生成
- 出力:構造化JSON(スキル・経験年数・強み3点・推薦コメント)
両パイプライン共通で、個人情報マスキングレイヤーが入ります。これが「法務OKを取るための鍵」でもあります。
実装環境:
- Python 3.11以上
- anthropic SDK 0.25以上(2026年5月時点の最新安定版)
- google-auth, gspread(Sheets API連携)
- pdfplumber 0.11以上(PDF解析)
- python-dotenv(環境変数管理)
# 依存関係インストール
pip install anthropic gspread google-auth pdfplumber python-dotenv
Pillar 1実装:Google Sheetsから媒体別求人票を一括生成する
まずGoogle Sheetsの構造を決めます。求人マスタシートには以下のカラムを想定します。
A: job_id
B: job_title(職種名)
C: job_description_raw(生の仕事内容・200〜400字)
D: required_skills(必須スキル・カンマ区切り)
E: preferred_skills(歓迎スキル)
F: salary_range(給与帯・例: 400万〜600万円)
G: location(勤務地)
H: work_style(勤務形態・例: フルリモート可)
このマスタから、以下の4媒体向けテキストを生成する出力シートを用意します。
col_site: 自社サイト用(600〜800字・丁寧な敬語・企業文化を前面に)
col_board_a: 大手求人媒体A用(300〜400字・箇条書き・検索最適化重視)
col_board_b: 大手求人媒体B用(250〜350字・端的・応募ハードルを下げるトーン)
col_sns: SNS/カジュアル採用用(150〜200字・体言止めOK・共感ワード)
スクリプト実装
"""
job_rewrite.py — 求人票媒体別リライトスクリプト
実行: python job_rewrite.py --sheet_id YOUR_SHEET_ID --worksheet 求人マスタ
"""
import os
import re
import time
import argparse
import anthropic
import gspread
from google.oauth2.service_account import Credentials
from dotenv import load_dotenv
load_dotenv()
# ── 定数 ──────────────────────────────────────────────
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
GOOGLE_SERVICE_ACCOUNT_JSON = os.getenv("GOOGLE_SERVICE_ACCOUNT_JSON", "service_account.json")
MODEL = "claude-sonnet-4-5" # 2026年5月時点
# 媒体別設定
MEDIA_CONFIG = {
"site": {
"name": "自社サイト",
"min_chars": 600,
"max_chars": 800,
"tone": "丁寧な敬語・企業文化と成長機会を強調・応募者が働く姿をイメージしやすいように",
"ng_words": [], # 自社は比較的自由
},
"board_a": {
"name": "大手求人媒体A(Indeed想定)",
"min_chars": 300,
"max_chars": 400,
"tone": "事実中心・箇条書き推奨・検索されやすい職種名を文頭に・給与と勤務地を早期明示",
"ng_words": ["絶対", "業界最高", "急募", "年齢不問(実際に年齢で弾く場合は使用不可)"],
},
"board_b": {
"name": "大手求人媒体B(Wantedly想定)",
"min_chars": 250,
"max_chars": 350,
"tone": "「なぜこの仕事をするのか」というミッション・共感・仲間感を前面に。給与より面白さを押し出す",
"ng_words": ["高給", "稼げる", "ノルマ"],
},
"sns": {
"name": "SNS/カジュアル採用",
"min_chars": 150,
"max_chars": 200,
"tone": "体言止めOK・読みやすい改行・絵文字は使わない・応募のハードルを下げる・「話だけ聞きたい」を歓迎",
"ng_words": ["経験者のみ", "即戦力のみ"],
},
}
def build_rewrite_prompt(job: dict, media_key: str) -> str:
config = MEDIA_CONFIG[media_key]
ng_word_str = "・".join(config["ng_words"]) if config["ng_words"] else "なし"
return f"""あなたは採用専門のコピーライターです。以下の求人マスタ情報を、指定された媒体向けにリライトしてください。
## 求人マスタ情報
- 職種名: {job['job_title']}
- 仕事内容(原文): {job['job_description_raw']}
- 必須スキル: {job['required_skills']}
- 歓迎スキル: {job.get('preferred_skills', 'なし')}
- 給与帯: {job['salary_range']}
- 勤務地: {job['location']}
- 勤務形態: {job.get('work_style', '応相談')}
## 媒体: {config['name']}
## トーン・書き方の指示: {config['tone']}
## 文字数: {config['min_chars']}〜{config['max_chars']}字(厳守)
## 使用禁止ワード: {ng_word_str}
## 制約
- 事実情報(給与・勤務地・スキル要件)を変えないこと
- 確認できない情報を付け加えないこと
- 仮定した内容があれば文末に「※(仮定):〜」と明記すること
- 出力は求人票本文のみ。前置きや説明は不要
## 出力
求人票本文({config['min_chars']}〜{config['max_chars']}字):"""
def rewrite_job(client: anthropic.Anthropic, job: dict, media_key: str) -> str:
prompt = build_rewrite_prompt(job, media_key)
message = client.messages.create(
model=MODEL,
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return message.content[0].text.strip()
def check_ng_words(text: str, ng_words: list) -> list:
"""NGワードを検出して一覧を返す"""
found = []
for word in ng_words:
if re.search(word, text):
found.append(word)
return found
def process_sheet(sheet_id: str, worksheet_name: str):
# Google Sheets認証
scopes = [
"https://www.googleapis.com/auth/spreadsheets",
"https://www.googleapis.com/auth/drive",
]
creds = Credentials.from_service_account_file(GOOGLE_SERVICE_ACCOUNT_JSON, scopes=scopes)
gc = gspread.authorize(creds)
sh = gc.open_by_key(sheet_id)
ws = sh.worksheet(worksheet_name)
# データ読み込み
records = ws.get_all_records()
print(f"求人数: {len(records)}件を処理します")
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
results = []
for i, row in enumerate(records):
job_id = row.get("job_id", f"row_{i+2}")
print(f"処理中: {job_id} / {row.get('job_title', '')}")
job_results = {"job_id": job_id}
for media_key in MEDIA_CONFIG.keys():
generated = rewrite_job(client, row, media_key)
# NGワードチェック
ng_found = check_ng_words(generated, MEDIA_CONFIG[media_key]["ng_words"])
if ng_found:
print(f" ⚠️ [{media_key}] NGワード検出: {ng_found} → 要人間レビュー")
generated = f"【要レビュー:NGワード候補あり({', '.join(ng_found)})】\n" + generated
job_results[media_key] = generated
time.sleep(0.5) # レート制限対策
results.append(job_results)
# 出力シートへ書き込み
try:
out_ws = sh.worksheet("媒体別出力")
except gspread.WorksheetNotFound:
out_ws = sh.add_worksheet(title="媒体別出力", rows=500, cols=20)
header = ["job_id"] + list(MEDIA_CONFIG.keys())
out_ws.update("A1", [header])
rows_to_write = [[r["job_id"]] + [r[k] for k in MEDIA_CONFIG.keys()] for r in results]
out_ws.update("A2", rows_to_write)
print(f"✅ 完了: {len(results)}件を「媒体別出力」シートに書き込みました")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--sheet_id", required=True)
parser.add_argument("--worksheet", default="求人マスタ")
args = parser.parse_args()
process_sheet(args.sheet_id, args.worksheet)
このスクリプトのポイントを補足します。
MEDIA_CONFIGディクショナリに媒体ごとのルールをまとめているため、新しい媒体を追加する場合はここにキーを追加するだけです。NGワードリストは各媒体の利用規約を読んで随時更新してください——特に求人媒体は掲載ガイドラインが変わることがあります。
レート制限対策としてtime.sleep(0.5)を入れています。件数が多い場合は並列化も可能ですが、Anthropicのレート制限(RPM・TPM)を確認してから設定してください(anthropic.comの料金・利用制限ページ参照)。
Pillar 2実装:職務経歴書PDFを構造化JSON+3行サマリに変換する
こちらは2ステップの処理です。まずPDFからテキストを抽出し、次に個人情報をマスキングしてからClaudeに渡します。
Step A:PDF→テキスト抽出
"""
pdf_extractor.py — 職務経歴書PDFのテキスト抽出モジュール
"""
import pdfplumber
import re
from typing import Optional
def extract_text_from_pdf(pdf_path: str) -> str:
"""
pdfplumberでPDFからテキストを抽出する。
テーブルが含まれる場合は構造を保持しながら結合する。
"""
full_text = []
with pdfplumber.open(pdf_path) as pdf:
for page_num, page in enumerate(pdf.pages, 1):
# テーブルを優先抽出
tables = page.extract_tables()
if tables:
for table in tables:
for row in table:
# Noneをフィルタして結合
cleaned = [cell.strip() if cell else "" for cell in row]
full_text.append(" | ".join(cleaned))
# 通常テキストも追加(テーブル外の文章)
text = page.extract_text(x_tolerance=3, y_tolerance=3)
if text:
full_text.append(text)
return "\n".join(full_text)
def mask_pii(text: str) -> tuple[str, dict]:
"""
個人情報(PII)をマスクする。
元の値をlookup辞書に保存して返す(必要に応じて復元可能)。
Returns:
masked_text: マスク済みテキスト
pii_map: {PLACEHOLDER: 元の値} の辞書
"""
pii_map = {}
counter = {"name": 0, "phone": 0, "email": 0, "address": 0}
# メールアドレス
def replace_email(m):
counter["email"] += 1
key = f"[EMAIL_{counter['email']}]"
pii_map[key] = m.group(0)
return key
text = re.sub(r'[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}', replace_email, text)
# 電話番号(日本の形式)
def replace_phone(m):
counter["phone"] += 1
key = f"[PHONE_{counter['phone']}]"
pii_map[key] = m.group(0)
return key
text = re.sub(r'0\d{1,4}[-\s]?\d{1,4}[-\s]?\d{4}', replace_phone, text)
# 住所(都道府県から始まるパターン)
def replace_address(m):
counter["address"] += 1
key = f"[ADDRESS_{counter['address']}]"
pii_map[key] = m.group(0)
return key
text = re.sub(
r'(東京都|大阪府|神奈川県|愛知県|福岡県|北海道|京都府|兵庫県|埼玉県|千葉県)[^\n]{5,50}',
replace_address, text
)
# 注意: 氏名のマスキングは固有名詞NERが必要なため、
# 「氏名:」「名前:」のラベル付き箇所のみ対象とする簡易版
def replace_named_name(m):
counter["name"] += 1
key = f"[NAME_{counter['name']}]"
pii_map[key] = m.group(2)
return m.group(1) + key
text = re.sub(r'(氏名[::]\s*)([^\n\s]{2,8})', replace_named_name, text)
return text, pii_map
氏名マスキングについて補足します。NER(固有表現抽出)なしで全ての氏名を完全マスクするのは難しいため、「氏名:」「名前:」ラベルの後に続くパターンだけを対象にしています。より精度を上げたい場合はGiNZA等の日本語NERライブラリを使うか、Claudeに「このテキストから氏名と思われる固有名詞をリストアップして」と聞く2段階処理が有効です。
Step B:マスク済みテキスト→構造化JSON+サマリ生成
"""
candidate_summary.py — 候補者サマリ生成モジュール
"""
import json
import anthropic
from pdf_extractor import extract_text_from_pdf, mask_pii
MODEL = "claude-sonnet-4-5"
SUMMARY_PROMPT_TEMPLATE = """あなたは人材紹介会社のキャリアアドバイザーをサポートするAIアシスタントです。
以下の職務経歴書テキスト(個人情報はマスク済み)を解析し、JSON形式で構造化してください。
## 職務経歴書テキスト(マスク済み)
{resume_text}
## 出力形式(JSONのみ出力。説明文は不要)
{{
"years_of_experience": "推定総経験年数(例: 5年)",
"current_or_last_role": "直近の役職・職種",
"industry_history": ["過去に在籍した業界のリスト"],
"key_skills": ["スキルのリスト(上位5〜8個)"],
"management_experience": "あり(○名規模)またはなし",
"highlight_3lines": [
"ハイライト1(30字以内)",
"ハイライト2(30字以内)",
"ハイライト3(30字以内)"
],
"recommendation_comment": "企業側への推薦コメント(100〜150字。この候補者の強みと企業にマッチしそうな理由)",
"notes_for_review": "CAが人間レビューで確認すべき点・不明点(あれば記載)"
}}
## 制約
- 職務経歴書に明記されていない事実を推測で断定しないこと
- 不明な箇所は「記載なし」または「確認要」と記載すること
- recommendation_commentは「〜と推察されます」「〜の可能性があります」という推測表現を使い、断定しないこと"""
def generate_candidate_summary(pdf_path: str, client: anthropic.Anthropic) -> dict:
"""
PDFパスを受け取り、候補者サマリJSONを返す。
Returns:
result: {
"summary": {...}, # Claudeの出力JSON
"pii_map": {...}, # マスクした個人情報の対応表(社内保管用)
"raw_masked_text": "..." # Claudeに渡したテキスト(ログ用)
}
"""
# Step 1: PDF抽出
raw_text = extract_text_from_pdf(pdf_path)
# Step 2: 個人情報マスキング
masked_text, pii_map = mask_pii(raw_text)
# 文字数制限(Claudeのコンテキスト節約)
if len(masked_text) > 8000:
masked_text = masked_text[:8000] + "\n...[テキスト長のため省略]"
# Step 3: Claude API呼び出し
prompt = SUMMARY_PROMPT_TEMPLATE.format(resume_text=masked_text)
message = client.messages.create(
model=MODEL,
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
response_text = message.content[0].text.strip()
# JSON抽出(コードブロックが混入する場合に対処)
if "```json" in response_text:
response_text = response_text.split("```json")[1].split("```")[0].strip()
elif "```" in response_text:
response_text = response_text.split("```")[1].split("```")[0].strip()
try:
summary_json = json.loads(response_text)
except json.JSONDecodeError as e:
# パース失敗時はrawテキストを格納してレビューを促す
summary_json = {
"parse_error": str(e),
"raw_response": response_text,
"notes_for_review": "JSON解析エラー。人間による確認が必要です。"
}
return {
"summary": summary_json,
"pii_map_key_count": len(pii_map), # ログ用。実際のpii_mapは別ストレージに保管
"raw_masked_text_length": len(masked_text),
}
# 使用例
if __name__ == "__main__":
import os
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
result = generate_candidate_summary("./sample_resume.pdf", client)
print("=== 候補者サマリ ===")
print(json.dumps(result["summary"], ensure_ascii=False, indent=2))
print(f"\nマスクされた個人情報: {result['pii_map_key_count']}項目")
print("※ 内容は必ず担当CAが確認・校正してから企業側に共有してください")
個人情報マスキング設計:法務部門に「OK」を出してもらうための具体的な説明材料
実装の技術的な側面よりも、「社内でこのシステムをどう承認してもらうか」という問いの方が実は難しかったりします。以下は、私が支援した導入検討の現場でよく使っていた説明の枠組みです(想定シナリオ・実装パターンとして参照ください)。
法務に見せる3層の説明
層1:データの流れの透明化
「職務経歴書PDFはサーバーに保存しない。処理のためだけにメモリ上に展開し、終了後に廃棄する」「Claudeに送るのはマスキング済みテキストのみ。氏名・連絡先・住所はプレースホルダーに置換してある」という説明は、多くの法務担当者が安心できるポイントです。
層2:職業安定法との整合性
職業安定法第51条の趣旨(求職者情報の適切な管理)に照らして、「AIは要約・抽出のための道具であり、求職者情報の第三者提供の意思決定はすべて人間のCAが行う」という位置付けを明確にします。AIが生成したサマリは「下書き」であり、CAが内容を確認・承認してから企業側に提示する運用ルールを文書化してください。
法的な詳細は弁護士・社会保険労務士に相談することを強く推奨します。
層3:同意取得と説明義務
求職者登録フォームまたは面談時に「業務処理のためにAIツールを使用することがある」旨の説明と同意取得を追加します。個人情報保護法の観点からも、利用目的の特定・通知は必須です。
Anthropicのデータ処理ポリシーの確認方法
APIを通じてAnthropicに送ったデータがモデルのトレーニングに使われるかどうかは、Anthropicの利用規約およびデータ処理補足契約(DPA)に依存します。エンタープライズ契約や特定のAPIプランではデータの取り扱いが異なる場合があるため、必ずAnthropicの公式サイト(anthropic.com)で最新のプライバシーポリシーとAPI利用規約を確認し、必要に応じてDPAを締結してください。
Claude Codeの権限(permission)設計:外部送信を絞る
Claude Codeを使ってこれらのスクリプトを開発・テストするとき、CLAUDE.mdファイルを使ってClaude Codeの動作範囲を制限することが重要です。特に個人情報を含む職務経歴書を扱う環境では、意図せずファイルが外部に送信されるリスクを設計段階で排除します。
# CLAUDE.md — 人材業務自動化プロジェクト
## ⚠️ 重要:このプロジェクトでのClaude Codeの動作制限
### 許可する操作
- ./src/ 以下のPythonファイルの読み書き・実行
- ./tests/ 以下のテストファイルの実行
- pip install(requirements.txtに記載されたパッケージのみ)
- Google Sheetsへのデータ書き込み(本番用シートIDのみ)
### 禁止する操作
- ./data/resumes/ 以下のPDFファイルを外部URLにアップロードすること
- APIキーを含む.envファイルの内容を出力・ログ出力すること
- git commit に個人情報含有ファイルを追加すること
- 未確認の外部サービス(Anthropic API以外)へのデータ送信
### データ分類
- ./data/resumes/ : 機密(職務経歴書PDF。ローカル処理のみ)
- ./data/output/ : 社内利用(マスク済み出力。Slack/メール共有前に確認必須)
- ./src/ : コード(Git管理OK)
このCLAUDE.mdファイルをプロジェクトルートに置くと、Claude Codeがセッション開始時に読み込みます。明示的に「禁止する操作」を書いておくことで、意図しないファイル操作のリスクを下げられます。
Claude Codeのpermissionシステムの詳細はAnthropicの公式ドキュメント(code.claude.com)を参照してください。
媒体別NGワード管理:辞書ファイルの運用設計
NGワードの管理をconfig/ng_words.jsonとして外部化すると、エンジニア以外のRA担当者がメンテナンスできます。
{
"global": [
"業界最高水準",
"絶対",
"確実に稼げる",
"高収入保証"
],
"board_a": {
"note": "Indeed掲載ガイドライン準拠(2026年5月版)。定期的に公式ガイドラインを確認してください。",
"words": [
"急募",
"すぐ稼げる",
"性別不問(実際に性別制限がある場合は不可)",
"若者向け(年齢差別に当たる表現)"
]
},
"board_b": {
"note": "Wantedly掲載ガイドライン準拠(確認日:2026-05-01)",
"words": [
"年収〇〇万以上確定",
"ノルマなし(実際にノルマがある場合)"
]
},
"sns": {
"note": "求人媒体ではないため規約制約は少ないが、景品表示法・職業安定法の観点で確認済み表現のみ使用",
"words": [
"絶対採用",
"100%内定"
]
}
}
このJSONをスクリプト側で読み込んで使います。
import json
def load_ng_words(config_path: str = "config/ng_words.json") -> dict:
with open(config_path, encoding="utf-8") as f:
config = json.load(f)
# globalと各媒体のNGワードをマージ
result = {}
global_words = config.get("global", [])
for media_key in ["board_a", "board_b", "sns", "site"]:
media_config = config.get(media_key, {})
result[media_key] = global_words + media_config.get("words", [])
return result
【要注意】よくある失敗パターン4選
❌ 失敗1:生成テキストをノーチェックで媒体に投稿する
Claude APIが生成した求人票テキストを、NGワードチェックと人間レビューを省略してそのまま媒体に投稿するのは危険です。
⭕ 正しいアプローチ:NGワード検査→担当RAのレビュー→投稿、という3ステップを必ず踏みます。求人媒体への虚偽表示は職業安定法違反になるリスクがあります。最終的な掲載内容に責任を持つのは人間です。
❌ 失敗2:職務経歴書の原本PDFをそのままAPIに送る
個人情報マスキングを省略して職務経歴書の生テキストをClaudeに渡すパターンです。処理が簡単になる反面、個人情報の取り扱いに関するコンプライアンスリスクが生まれます。
⭕ 正しいアプローチ:本記事のmask_pii()関数をベースに、必要なマスキングを実施してから送信します。マスキングの精度が不十分な場合は人間が目視確認してからAPIに渡してください。
❌ 失敗3:求人票の給与・スキル要件を「それっぽく」書き換えてしまう
AIが生成するテキストは時として原文の条件を曖昧にしたり、「歓迎スキル」を「必須スキル」のように強調したりすることがあります。プロンプトで「事実情報を変えないこと」と指定しても、完全には防げないケースがあります。
⭕ 正しいアプローチ:プロンプトに「給与・スキル要件・勤務地は原文の情報をそのまま使うこと。推測で補完しないこと」を明記し、生成後に担当RAが原文と照合して確認します。
❌ 失敗4:全媒体で同じプロンプトを使い回す
「とりあえず書いてください」という汎用プロンプトで全媒体分を生成しても、各媒体の文字数・トーン・ガイドラインに合わない出力になります。
⭕ 正しいアプローチ:本記事のMEDIA_CONFIGディクショナリのように、媒体ごとにトーン指定・文字数範囲・NGワードリストを明示的に分けます。媒体ごとのプロンプトを一度作れば、その後は設定変更だけで対応できます。
Google Sheetsとの連携:チームで使うための設計
「エンジニアが書いたスクリプトをRAやCAも使えるようにする」ための設計で重要な点を整理します。
シート構造の設計
ファイル: 求人管理_2026.gsheet
├── 求人マスタ(RAが入力するシート)
│ A: job_id B: job_title C: job_description_raw ...
│ ※ RAが原文を入力する
│
├── 媒体別出力(スクリプトが書き込むシート)
│ A: job_id B: site C: board_a D: board_b E: sns
│ ※ 読み取り専用で表示。レビュー後に手動コピー or API連携
│
└── NGワードフラグ(スクリプトが書き込む)
A: job_id B: media C: ng_words_detected D: review_status
※ "要レビュー"フラグが立った行をRAに通知
Google Apps Scriptからのトリガー(オプション)
「求人マスタシートに新規行が追加されたら自動でスクリプト実行」という設定をGoogle Apps Script(GAS)でトリガーできます。ただしGASからPythonスクリプトを直接呼ぶことはできないため、Cloud Run等の中間レイヤーが必要です。スモールスタートなら「毎朝9時にスクリプトをCronで実行」という単純な構成の方が管理しやすいケースが多いです。
候補者サマリの品質を上げるプロンプト改善:3つの技法
職務経歴書のフォーマットは本当にバラバラです。プロンプトでどこまでをClaude側に任せて、どこを明示的に指定するかの設計が出力品質に直結します。
技法1:Chain of Thoughtで解析ステップを分ける
CHAIN_OF_THOUGHT_PROMPT = """まず以下のステップで職務経歴書を分析してください。
ステップ1: 在籍企業と在籍期間の一覧を時系列で整理する
ステップ2: 各期間で担当した役割とスキルをリストアップする
ステップ3: 管理職・チームリード経験の有無と規模を特定する
ステップ4: 最も強みとなるスキルTOP5を選ぶ(選択理由も簡単に記載)
上記の分析結果を踏まえて、最終的なJSON出力を生成してください。
[以下は同じJSON出力フォーマット...]
"""
技法2:Few-shotで出力の「粒度感」を揃える
推薦コメントの文体が毎回バラバラになる場合、良いサンプルを1〜2件プロンプトに含めると揃いやすくなります。
FEW_SHOT_EXAMPLE = """
## 推薦コメントの例(参考にしてください)
良い例:
「製造業でのSCMシステム導入(5年)と、それに続くSI企業でのPM経験(3年)を持つ候補者と推察されます。
システム導入の上流から保守まで一貫して携わった可能性があり、製造業のITベンダー案件や
DX推進担当として活躍できる見込みがあります。経験業界との親和性を確認の上、ご検討ください。」
悪い例(使用禁止):
「優秀な人材です。ぜひ採用してください。」(根拠なし・断定的)
「年収500万円は確実に出せます。」(条件の断定)
"""
技法3:モデルへの役割付与とコンテキスト設定
SYSTEM_PROMPT = """あなたは人材紹介会社の熟練したキャリアアドバイザー(CA)です。
10年以上のキャリア支援経験があり、職務経歴書を読んで候補者の強みを的確に把握することが得意です。
重要な制約:
- 職務経歴書に書かれていない情報を推測で断定しない
- 不明点は「記載なし」「要確認」と正直に記載する
- AIが生成したコメントである旨を意識し、最終判断は人間のCAが行う前提で書く
- 個人情報(氏名・連絡先)はマスクされているため、それ以外の職歴情報のみで判断する"""
# API呼び出し時のsystem引数として使用
message = client.messages.create(
model=MODEL,
max_tokens=1024,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": prompt}]
)
運用フローの設計:エンジニアが作ってRAが使うシステムにするために
技術的に動くものを作っても、現場のRAやCAが使わなければ意味がありません。導入後の運用をどう設計するかが、実は一番大切なんです。
推奨する段階的な展開フロー
Phase 1(最初の2週間):並走期間
既存の手作業と並行してシステムを動かし、「AIの出力と人間が手作業で書いたものの差分」を毎日確認します。品質に問題がなければ、少しずつAI生成を本番運用に組み入れます。NGワードリストの精度もこの段階で調整します。
Phase 2(3〜4週目):部分自動化
「board_a向けリライト」に限定してAI生成を本番投入します。他媒体はまだ手作業を続けます。この段階で「どのくらい手直しが入るか」の実測データを取ります。
Phase 3(2ヶ月目〜):媒体の拡大と候補者サマリ導入
求人票リライトの品質が安定したら他媒体を追加し、並行して候補者サマリ生成のPoCを始めます。
レビュー担当者(RA/CA)向けのチェックポイント
以下をチェックリストとして提示すると、非エンジニアのRAでも品質管理を担えます。
- □ 給与帯・勤務地・スキル要件が原文と一致しているか
- □ NGワードフラグが立っている場合、そのワードが修正されているか
- □ 各媒体の文字数が規定範囲内か(ざっくり目視でOK)
- □ 読んでみて「これは自分が書いたものより良い or 許容範囲か」
- □ 候補者サマリの場合、職務経歴書の原文と矛盾する記述がないか
関連記事と横展開できる領域
本記事のパイプラインと組み合わせると効果が高い実装として、書類選考フローの自動化があります。求人票の生成と候補者サマリの生成を合わせると、求人要件との適合度スコアリングへの発展もできます。詳しくは 人材紹介会社の書類選考ワークフローをClaude Codeで自動化する実装ガイド を参照してください。
また、候補者管理のCRM的な使い方に興味がある方は Claude Codeによる採用エージェント・候補者管理の実装事例2026 も合わせてご覧ください。
パフォーマンスチューニング:件数が増えた時の対処
月に数百件の求人票リライトが必要になった場合、いくつかの最適化を検討できます。
バッチサイズと並列処理
import asyncio
import anthropic
async def rewrite_job_async(client, job, media_key, semaphore):
"""非同期版のリライト関数。並列実行のためのセマフォ付き。"""
async with semaphore:
# anthropicの非同期クライアントを使用
message = await client.messages.create(
model=MODEL,
max_tokens=1024,
messages=[{"role": "user", "content": build_rewrite_prompt(job, media_key)}]
)
return media_key, message.content[0].text.strip()
async def process_jobs_async(jobs: list, max_concurrent: int = 5):
"""
複数求人を並列処理する。
max_concurrent: 同時実行数(Anthropicのレート制限に合わせて調整)
"""
client = anthropic.AsyncAnthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
semaphore = asyncio.Semaphore(max_concurrent)
all_tasks = []
for job in jobs:
for media_key in MEDIA_CONFIG.keys():
task = rewrite_job_async(client, job, media_key, semaphore)
all_tasks.append((job["job_id"], task))
results = await asyncio.gather(*[t for _, t in all_tasks])
return results
並列実行数はmax_concurrentで制御します。Anthropicのレート制限(RPM/TPMの上限)はAPIキーのTierによって異なるため、anthropic.comの利用制限ページで確認してから設定してください。
プロンプトキャッシング
Anthropicのprompt cachingを使うと、同じシステムプロンプトを繰り返し使う場合にコストを削減できます(2026年5月時点でanthropicの公式ドキュメントで確認可能)。求人マスタが変わっても媒体別のトーン指示は変わらないため、MEDIA_CONFIGの内容をキャッシュ対象にするとコスト効率が上がります。
よくある質問と技術的なつまずきポイント
Q1: pdfplumberで表が正しく読み込めない場合はどうするか?
一部の職務経歴書PDFはスキャン画像ベースのため、pdfplumberでは空のテキストが返ります。その場合はOCRが必要です。PythonではpytesseractかeasyOCRが選択肢になりますが、日本語OCRの精度はドキュメントの品質に依存します。スキャン品質が低いPDFはエラーとして人間が手動入力するフローにする方が実用的な場合があります。
def is_scanned_pdf(pdf_path: str) -> bool:
"""スキャン画像ベースのPDFかどうかを判定する簡易チェック。"""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages[:2]: # 最初の2ページで判定
text = page.extract_text()
if text and len(text.strip()) > 50:
return False
return True # テキストがほぼ取れない = スキャン画像の可能性大
Q2: Claudeが出力するJSONのスキーマが安定しない場合は?
稀に出力JSONのキー名が変わったり、構造が崩れることがあります。Pydanticを使ったバリデーション層を追加すると堅牢になります。
from pydantic import BaseModel, Field
from typing import Optional
class CandidateSummary(BaseModel):
years_of_experience: str
current_or_last_role: str
industry_history: list[str]
key_skills: list[str]
management_experience: str
highlight_3lines: list[str] = Field(min_items=1, max_items=5)
recommendation_comment: str
notes_for_review: Optional[str] = None
# 使用例
try:
validated = CandidateSummary(**summary_json)
except Exception as e:
print(f"バリデーションエラー: {e} → 人間レビューへ")
Q3: 環境変数の管理はどうするべきか?
# .env ファイル(Gitには絶対コミットしない)
ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxx
GOOGLE_SERVICE_ACCOUNT_JSON=/path/to/service_account.json
# .gitignore に必ず追加
.env
service_account.json
data/resumes/
本番環境では.envファイルではなく、Google Cloud Secret ManagerやAWS Secrets Managerなどのシークレット管理サービスを使うことを推奨します。
まとめ:今日から始める3つのアクション
- 今日やること:pdf_extractor.pyの
extract_text_from_pdf()とmask_pii()をコピーして、手元にある職務経歴書(テスト用)でPythonを実行してみる。どんなテキストが取れるかを確認する。 - 今週中:MEDIA_CONFIGの4媒体設定を自社の実際の求人媒体に合わせてカスタマイズし、
job_rewrite.pyで1件の求人票を4媒体分生成してみる。出力品質を担当RAに確認してもらう。 - 今月中:法務・コンプライアンス部門と「APIに送るのはマスキング済みテキストのみ」という説明を行い、候補者サマリ生成のPoCを開始する。NGワードリストの初版を作成して運用フローを文書化する。
次回予告:人材紹介のCRM連携——生成したサマリを候補者管理システムに自動連携してSlack通知するまでの実装パターンを予定しています。
参考・出典
- Anthropic API Documentation — Getting Started(Anthropic、参照日:2026-05-31)
- 職業安定法・労働者派遣法に関するページ(厚生労働省、参照日:2026-05-31)
- Anthropic Privacy Policy(Anthropic、参照日:2026-05-31)


