
結論:GraphQL開発は「スキーマを正本にしてClaude Codeに実装させる」と速い
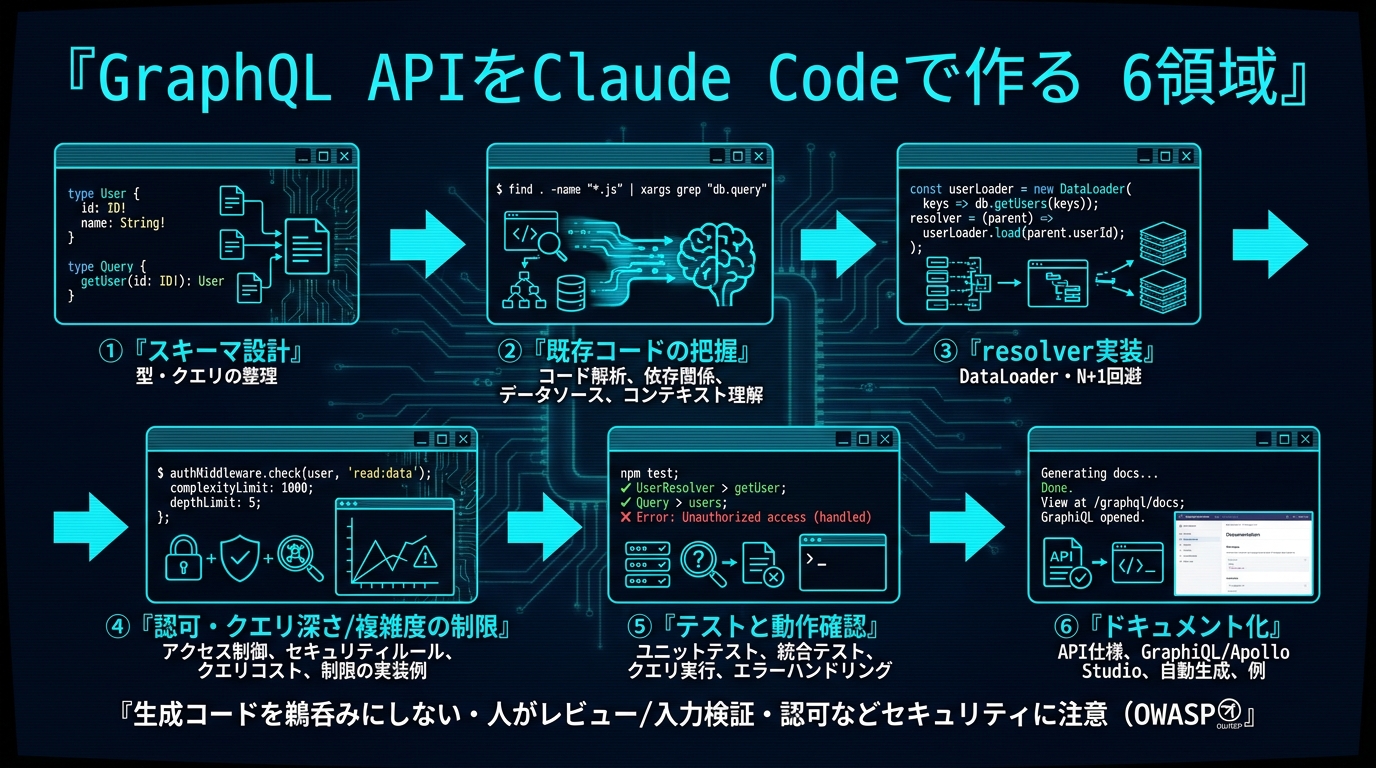
GraphQL APIをClaude Codeで作るときの肝は、いきなりresolverを書かせないことです。先にschema.graphqlという「正本(Source of Truth)」を固め、そこからtype・query・mutation・resolverを生成させる。この順番にするだけで、生成コードの手戻りが目に見えて減ります。本記事は2026年6月時点のClaude Code公式ドキュメントとGraphQL公式(graphql.org)の推奨に沿って、設計から実装・テスト・運用までの実践手順を、指示例とコード例つきでまとめました。
- 結論:スキーマ駆動(schema-first)でClaude Codeを動かすと、REST的な「エンドポイント乱立」を避けつつ型安全に実装できる。
- 要点3つ:①
CLAUDE.mdにGraphQL規約を書く ②スキーマ→resolverの順で生成させる ③N+1・クエリ深さ・認可は人が必ずレビューする。 - 対象読者:GraphQLサーバー(Apollo Server / GraphQL Yoga 等)を実装・運用するバックエンドエンジニア、PM、Claude Code導入検討者。
- 今日やること:手元のプロジェクトに最小スキーマを置き、Claude Codeに「このスキーマからresolverの雛形を作って」と頼んでみる。
正直に言うと、最初にやらかしたのは「GraphQLサーバー作って」だけ投げて、いきなり完成形を吐かせようとしたパターンでした。返ってきたのはそれっぽいコードなんですが、スキーマと実装がじわじわズレていて、後からフィールドを足すたびに整合が崩れる。GraphQLは「型システムそのものが契約」なので、契約(スキーマ)を先に固定する。この一点を押さえると、Claude Codeの生成精度が一段上がります。
① 設計:スキーマファーストでtype・query・mutationを整理する
GraphQL公式(graphql.org/learn)でも、APIは「クライアントが必要なデータの形」を起点に設計するのが基本です。RESTのようにエンドポイントを並べるのではなく、1つのエンドポイントに対してスキーマで表現する。まずは扱うドメイン(例:ブログのPostとUser)を型として書き出します。
Claude Codeへの指示はこう出しました。
あなたはGraphQLのスキーマ設計者です。次の要件からschema.graphqlを書いてください。
- Post(id, title, body, published, author, createdAt)
- User(id, name, email, posts)
- Query: posts(published: Boolean), post(id: ID!), user(id: ID!)
- Mutation: createPost(input: CreatePostInput!), publishPost(id: ID!)
制約:
- ID は ID! 型、必須フィールドは非null(!)で表現
- ページネーション余地を残すが今回は未実装でよい(コメントで明記)
- input は専用の input type に分離する出てきたスキーマはこんな形です。生成された内容は必ず目で追って、必須/任意(!の有無)が意図通りか確認します。
type Post {
id: ID!
title: String!
body: String!
published: Boolean!
author: User!
createdAt: String!
}
type User {
id: ID!
name: String!
email: String!
posts: [Post!]!
}
input CreatePostInput {
title: String!
body: String!
authorId: ID!
}
type Query {
posts(published: Boolean): [Post!]!
post(id: ID!): Post
user(id: ID!): User
}
type Mutation {
createPost(input: CreatePostInput!): Post!
publishPost(id: ID!): Post!
}ここで決めておくと後がラクなのが「nullの扱い」です。GraphQLでは非nullフィールド(!)の解決が失敗すると、エラーが親フィールドまで伝播します。author を User! にした以上、authorが必ず取れる前提を満たすコードが要る——この設計判断は人がやるべきところです。
② 既存コードの把握:CLAUDE.mdにGraphQL規約を書いてから読ませる
Claude CodeはプロジェクトルートやサブディレクトリのCLAUDE.mdをメモリとして読み込みます(公式: Claude Code memory)。GraphQL案件では、ここに「うちのGraphQL規約」を書いておくと、生成コードが一気に自分たちのスタイルに寄ります。
実際に置いているCLAUDE.mdの抜粋です。
# GraphQL 実装規約
- サーバー: Apollo Server v4(@apollo/server)
- スキーマは schema.graphql を正本とし、resolver は src/resolvers/ に型ごとに分割
- DataLoader を使い N+1 を必ず回避する(User.posts, Post.author など関連解決は batch 化)
- 認可は resolver の最上段で context.user を検証してから実行
- エラーは GraphQLError + extensions.code(UNAUTHENTICATED / FORBIDDEN / BAD_USER_INPUT)で返す
- 入力検証は zod で input ごとに行う既存リポジトリに後から入る場合は、いきなり書き換えさせず「現状把握」から頼むのが安全です。
このリポジトリのGraphQL構成を調査して、次を箇条書きで報告してください。
1. スキーマ定義の場所と分割方針(SDL or code-first か)
2. resolver の登録方法と DataLoader の有無
3. 認証・認可がどこで効いているか
4. N+1 が起きていそうな関連フィールド
まだコードは変更しないでください。「まだ変更しないで」を付けるのが地味に効きます。調査と実装を分けると、こちらが構成を理解しないまま大改修される事故を防げます。
③ 実装:resolver・DataLoader・エラーハンドリングを規約に沿わせる
スキーマとCLAUDE.mdが揃ったら、resolver実装に入ります。GraphQLで最初にハマるのが N+1問題です。postsを10件取ったあと、各PostのauthorをそれぞれDBに問い合わせると11回クエリが飛ぶ。これはDataLoaderでバッチ化するのが定石です。
指示と、生成させたDataLoaderの例です(Apollo Server v4 + DataLoader想定)。
// 指示:
// User.posts と Post.author の N+1 を DataLoader で解消して。
// context にローダーを差し込み、各 resolver はローダー経由で関連を取得する形にして。
import DataLoader from "dataloader";
export function createLoaders(db) {
return {
userById: new DataLoader(async (ids) => {
const rows = await db.user.findMany({ where: { id: { in: ids } } });
const map = new Map(rows.map((u) => [u.id, u]));
return ids.map((id) => map.get(id) ?? null);
}),
postsByAuthorId: new DataLoader(async (authorIds) => {
const rows = await db.post.findMany({
where: { authorId: { in: authorIds } },
});
return authorIds.map((aid) =>
rows.filter((p) => p.authorId === aid)
);
}),
};
}resolver側はローダーを呼ぶだけにします。エラーは「文字列をthrow」ではなく、コード付きのGraphQLErrorで返すよう統一させます。
import { GraphQLError } from "graphql";
export const resolvers = {
Query: {
post: async (_p, { id }, ctx) => {
const post = await ctx.db.post.findUnique({ where: { id } });
if (!post) {
throw new GraphQLError("Post not found", {
extensions: { code: "NOT_FOUND" },
});
}
return post;
},
},
Post: {
// N+1 を避けるため author は loader 経由
author: (post, _a, ctx) => ctx.loaders.userById.load(post.authorId),
},
User: {
posts: (user, _a, ctx) => ctx.loaders.postsByAuthorId.load(user.id),
},
Mutation: {
createPost: async (_p, { input }, ctx) => {
if (!ctx.user) {
throw new GraphQLError("Login required", {
extensions: { code: "UNAUTHENTICATED" },
});
}
// 入力検証はここで(次節)
return ctx.db.post.create({ data: { ...input, published: false } });
},
},
};認可(ctx.userのチェック)と入力検証は、Claude Codeが省略しがちな箇所です。生成直後に必ず「全mutationの先頭で認可しているか」を自分の目で確認してください。
実装の進め方(おすすめ順)
- schema.graphql を確定させる(型と必須/任意を人が決める)。
- CLAUDE.md にGraphQL規約を追記し、Claude Codeに読ませる。
- resolverの「雛形だけ」を生成させ、DB接続はモックで通す。
- DataLoaderを導入し、関連フィールド(author・posts等)をバッチ化する。
- 認可・入力検証・エラーコードを各resolverに差し込む。
- テストを生成して挙動を固定し、最後にクエリ深さ・複雑度の上限を入れる。
④ 入力検証とセキュリティ:ここは生成を鵜呑みにしない
GraphQLは1エンドポイントで柔軟にクエリできる反面、攻撃面も独特です。OWASPのGraphQL Cheat Sheetでも、クエリ深さ制限・複雑度制限・introspectionの本番制御・入力検証が推奨されています。Claude Codeに任せきりにせず、次を明示的に依頼します。
入力検証はzod等でinput typeごとに行わせます。
import { z } from "zod";
const CreatePostSchema = z.object({
title: z.string().min(1).max(200),
body: z.string().min(1).max(50000),
authorId: z.string().uuid(),
});
// resolver 内
const parsed = CreatePostSchema.safeParse(input);
if (!parsed.success) {
throw new GraphQLError("Invalid input", {
extensions: { code: "BAD_USER_INPUT", issues: parsed.error.issues },
});
}悪意あるネストクエリ(深い再帰で負荷をかける攻撃)対策として、深さ・複雑度の上限も入れます。
あなたはGraphQLのセキュリティ担当です。次を実装してください。
- クエリの最大深さを 7 に制限(depth limit)
- クエリ複雑度の上限を設け、超過時は実行前に拒否
- 本番環境では introspection を無効化(開発のみ有効)
- レート制限の方針をコメントで提案
OWASP GraphQL Cheat Sheet の推奨に沿うこと。ただし——ここが本記事で一番伝えたいところですが、生成された上限値(深さ7・複雑度の閾値)は、あなたのスキーマに対して妥当とは限りません。正当なクエリが弾かれないか、必ず実トラフィックで検証してください。認証・認可・入力検証は、AIが「それっぽく」書けてしまうぶん、人のレビューが最後の砦です。
⑤ テストと動作確認:クエリ単位で挙動を固定する
GraphQLのテストは「実際に投げるクエリ文字列」を使って書くと安定します。Claude Codeにテストを生成させるときも、クエリ例を渡すと精度が上がります。
次のresolverのテストを Vitest で書いてください。
- query { post(id: "存在しないID") } → errors に code NOT_FOUND
- mutation createPost を未ログインで実行 → code UNAUTHENTICATED
- User.posts が N+1 にならない(loader が1回だけ呼ばれる)ことを spy で検証
DBはインメモリのモックを使い、ネットワークには出ないこと。動作確認の手順は次の通りです。
- 開発サーバーを起動し、GraphQL Playground / Apollo Sandbox でスキーマがロードされるか見る。
- 正常系クエリ(
posts取得)を投げ、想定の型で返るか確認する。 - 異常系(不正ID・未認証mutation)を投げ、
extensions.codeが期待通りか確認する。 - 関連フィールドを含むクエリを投げ、DBログでクエリ回数が増殖していないか(N+1が消えているか)を見る。
- 深いネストクエリを投げ、depth limitが効くか確認する。
「テストが通った」で安心せず、生成されたモックが本物のDB挙動と乖離していないかは別途見ます。AIのテストは「自分が書いた実装に都合よく緑になる」ことがあるので、最低1本は手で書いたテストを混ぜると安心です。
⑥ ドキュメント化:スキーマから仕様を生成して落差を埋める
GraphQLはスキーマ自体がドキュメントですが、フロント担当やレビュアー向けに人間可読な説明があると親切です。Claude Codeにスキーマを読ませて、フィールドの意味・代表的なクエリ例・エラーコード一覧をMarkdownで出させます。
schema.graphql を読んで docs/graphql.md を生成してください。
- 各 type / query / mutation の用途を1行説明
- 代表的なクエリ・mutationの実例(変数つき)
- extensions.code の一覧と発生条件
- 認可が必要な操作に🔒マークを付ける
スキーマに無いフィールドは書かないこと(憶測禁止)。「スキーマに無いものは書くな」を必ず添えます。これを付けないと、実装していないページネーション引数などを“ある前提”で書いてしまうことがあります。生成後はスキーマと突き合わせて、嘘がないかをこちらで確認します。
⑦ よくある失敗パターンと回避策
実際に踏んだ落とし穴を、❌と⭕で並べます。
- ❌ 「GraphQLサーバー作って」だけ投げる → スキーマと実装が乖離。⭕ 先に
schema.graphqlを確定させ、そこからresolverを生成させる。 - ❌ 関連フィールドを素直にDB問い合わせ → N+1で本番が詰まる。⭕ DataLoaderでバッチ化する規約をCLAUDE.mdに明記。
- ❌ 認可をresolverごとに書き忘れる → 未ログインでもmutationが通る。⭕ 全mutation先頭の
ctx.user検証を人がレビューで担保。 - ❌ introspectionを本番で開けっ放し → スキーマ構造が丸見え。⭕ 本番は無効化し、開発のみ有効にする(OWASP推奨)。
- ❌ 深さ・複雑度の上限をAIの初期値のまま採用 → 正当なクエリが弾かれる/弾けない。⭕ 実トラフィックで閾値を調整する。
段階的に導入するロードマップ
- 第1週:最小スキーマ(Post/User)でClaude Codeにresolver雛形を作らせ、流れを体感する。
- 第2週:CLAUDE.mdにGraphQL規約を整備し、DataLoaderとエラーコードを標準化する。
- 第3週:認可・入力検証・depth/complexity制限を入れ、テストで固定する。
- 第4週:既存RESTからの段階移行や、スキーマからのドキュメント自動生成まで広げる。
よくある質問(FAQ)
Q. Claude CodeはGraphQL専用の機能を持っていますか?
A. いいえ。Claude Codeは汎用のコーディングエージェントで、GraphQL専用コマンドはありません(2026年6月時点・公式ドキュメント基準)。スキーマやCLAUDE.mdといった「文脈」を与えることで、GraphQL実装に最適化します。
Q. schema-firstとcode-first、どちらがClaude Codeと相性がいいですか?
A. どちらでも動きますが、スキーマを正本にできるschema-firstの方が、生成と実装のズレを検知しやすく、レビューがラクです。
Q. 生成されたresolverをそのまま本番に出していい?
A. ダメです。特に認可・入力検証・N+1・クエリ制限は人が必ずレビューしてください。AIは「動くが安全でない」コードを自然に書きます。
まとめ:今日から始める3つのアクション
- 手元のプロジェクトに最小の
schema.graphqlを置き、Claude Codeに「このスキーマからresolver雛形を作って」と頼む。 - CLAUDE.mdにGraphQL規約(DataLoader必須・エラーコード・認可方針)を1ページ書く。
- 生成コードのうち「認可・入力検証・クエリ深さ制限」の3点を、自分の目でレビューする習慣にする。
次回は、このGraphQLサーバーに認証を載せる実装(トークン検証・context注入)を、Claude Codeでどう進めるかを掘り下げます。
あわせて読みたい
- Claude CodeでバックエンドAPI開発を効率化する実践ガイド(REST中心のバックエンド実装と比較して読むと違いがわかります)
- Claude Codeで認証・ログイン機能を実装する実践ガイド(GraphQLの認可と合わせて)
- Claude Codeでテスト自動化|QA効率化の実践ガイド(resolverのテスト設計に役立ちます)
著者プロフィール
佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援に携わる。著書『AIエージェント仕事術』(SBクリエイティブ)。


