
結論:ログ・監視(オブザーバビリティ)は「あとで入れる」ものではなく、機能を作るのと同時に設計するものです。Claude Codeを使えば、何を見たいか(目的)を言葉にした瞬間から、構造化ログの設計、メトリクス・トレースの実装、アラート方針までを一気通貫で形にできます。本記事は2026年6月時点のClaude Code公式仕様をベースに、実装の進め方と落とし穴を具体例つきでまとめた実践ガイドです。
- 要点1: オブザーバビリティはログ・メトリクス・トレースの3本柱。Claude Codeには「目的の言語化 → ログ設計 → 実装 → 可視化・アラート」の順で指示する。
- 要点2: ログは必ず構造化(JSON)し、レベル(DEBUG/INFO/WARN/ERROR)と相関ID(リクエストID)を最初から入れる。
- 要点3: 最大の落とし穴は機密情報・個人情報・認証情報をログに出してしまうこと。生成されたログ出力コードは必ず人がレビューする。
対象読者: アプリ・APIにログと監視を入れたいエンジニア/SRE/テックリード。今日できること: 自分のサービスのログ設計方針を1枚に書き出し、Claude Codeに構造化ロガーの雛形を作らせてレビューするところまで。
「障害が起きてから初めてログを見たら、肝心の情報が何も残っていなかった」——これ、正直あるあるなんです。私自身、社内ツールのバックエンドで500エラーが頻発したとき、ログにはErrorの一行しか出ておらず、どのリクエストで、どのユーザー操作で、どんな入力で落ちたのか、まったく追えませんでした。結局、本番にデバッグ用のprintを仕込んで再現を待つという、いちばんやってはいけない対応をする羽目になりました。
その反省から、新しい機能を作るときは「ログと監視を機能と同時に設計する」ようにしています。そしてその設計・実装の壁打ち相手として、Claude Codeがかなり優秀です。この記事では、Claude Codeを使ってアプリのログ・監視(オブザーバビリティ)をゼロから組み立てる流れを、実際の指示例とコード例つきで紹介します。
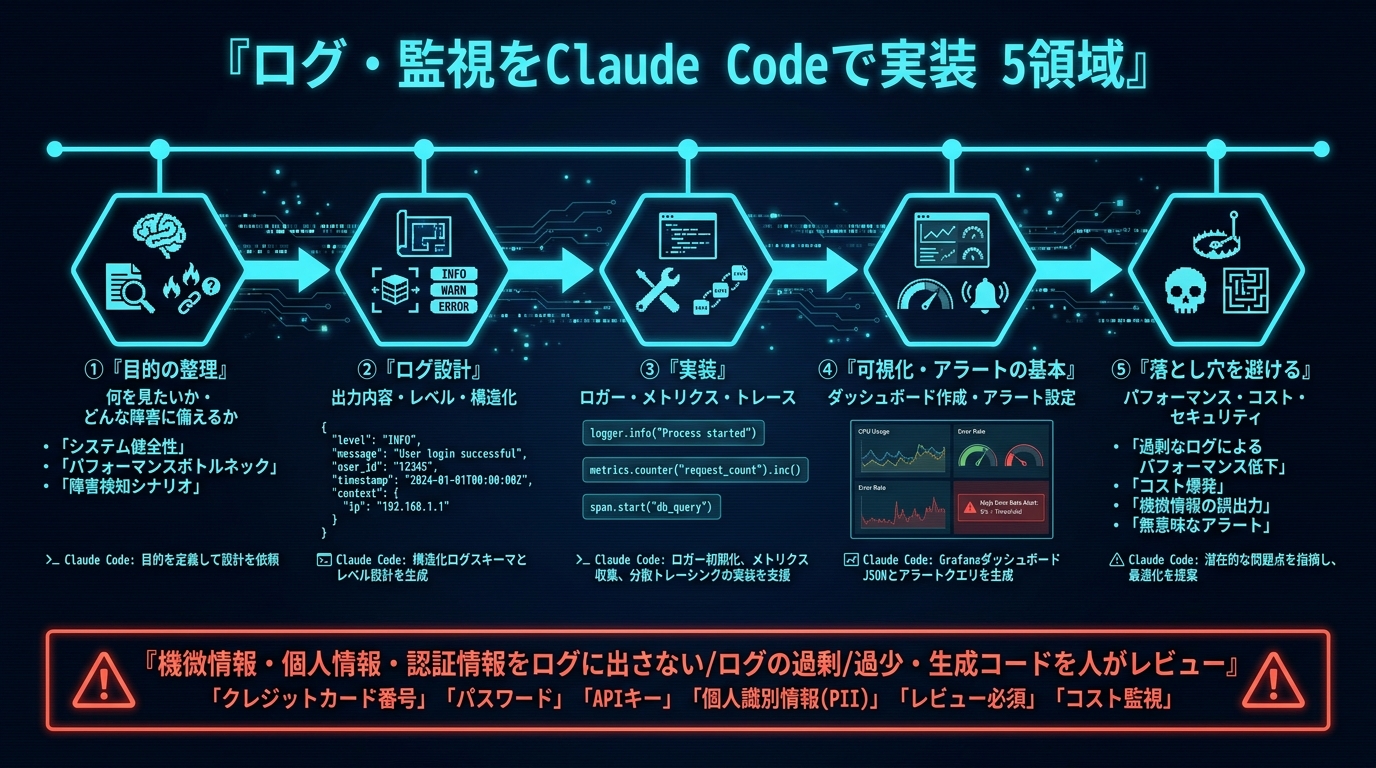
オブザーバビリティとは何か|まず「何を見たいか」を決める
オブザーバビリティ(可観測性)は、システムの外から出てくる出力だけを見て、内部で何が起きているかを推測できる状態を指します。一般に「ログ」「メトリクス」「トレース」の3本柱で語られます。
- ログ(Logs): 「いつ・何が起きたか」を時系列で記録する。1件1件のイベント。
- メトリクス(Metrics): リクエスト数、エラー率、レイテンシなど「数値の集計」。傾向や異常を面で捉える。
- トレース(Traces): 1つのリクエストが複数のサービス・関数をどう通ったかを線でつなぐ。ボトルネックの特定に使う。
ツールを入れる前に決めるべきは「何を見たいか」です。ここが曖昧なまま実装すると、ログは大量に出るのに肝心なときに役に立たない、という状態になります。Claude Codeに相談するときも、まずこの目的を言葉にして渡すのが一番効きます。
私が最初に投げる指示はだいたいこんな感じです。
このNode.js + Expressのバックエンドに、運用で使えるログ・監視を入れたい。
まず実装の前に、次を整理して提案してほしい。
目的:
- 障害時に「どのリクエストで・誰が・どんな入力で落ちたか」を再現なしで追えるようにする
- エラー率とレイテンシの悪化に気づけるようにする
制約:
- 個人情報(メール・氏名・電話)と認証トークンは絶対にログに出さない
- 既存のconsole.logは段階的に置き換える
この前提で「何を・どのレベルで・どんな構造で記録すべきか」のログ設計方針を、
表形式でまとめてから、実装方針を出して。いきなりコードは書かないで。
「いきなりコードを書かないで」と付けるのがコツです。先に設計を文章で出させると、こちらが意図とズレを確認してから実装に進めるので、手戻りが激減します。Claude Codeの拡張思考(深く考えさせるモード)を使えるなら、この設計フェーズで有効にすると整理の精度が上がります。
ログ設計|出力内容・レベル・構造化を最初に決める
ログ設計でまず固めるのは、(1) ログレベル、(2) 構造化フォーマット、(3) 必ず入れる共通フィールド、の3点です。
ログレベルを使い分ける
レベルは多すぎても運用が破綻します。最低限、次の4段階を意識すれば十分です。
- DEBUG: 開発時の詳細。本番では原則出さない(または絞る)。
- INFO: 正常系の節目。「リクエスト受信」「処理完了」など。
- WARN: 失敗ではないが注意が必要。「リトライした」「非推奨APIを使った」など。
- ERROR: 処理が失敗した。アラート対象になりうる。
構造化ログ(JSON)にする
「2026-06-07 ユーザーが注文を作成しました」のような自由文ログは、人間には読めても機械では検索・集計できません。運用で効くのは、フィールドが分かれた構造化ログ(JSON)です。後からログ基盤で「level=ERROR かつ user_id=123」のように絞り込めるのが大きい。
必ず入れたい共通フィールドはこのあたりです。
timestamp:ISO 8601形式の時刻level:ログレベルmessage:人間向けの短い説明request_id(相関ID):1リクエストを貫通して同じ値。障害追跡の生命線service/env:どのサービス・環境か
Claude Codeに構造化ロガーの雛形を作らせるときは、こう指示します。
JSON構造化ログを出すロガーを実装して。要件は次の通り。
- フィールド: timestamp(ISO8601), level, message, request_id, service, env, さらに任意の追加メタ
- レベルは debug/info/warn/error
- 本番(env=production)では debug を出力しない
- ログ出力前に、value が「機密フィールド名(password, token, authorization,
email, phone, card)」に一致するキーは "[REDACTED]" にマスクする共通処理を必ず通す
- 標準出力(stdout)に1行1JSONで出す(収集側で拾う前提)
ライブラリは pino を使ってよい。マスク処理は独自のserializerで実装し、
テストも一緒に書いて。
ポイントは、マスク処理を「共通の通り道」として実装させることです。各所のログ呼び出しで個別にマスクするとどこかで漏れます。ロガーの内部で一括マスクする設計にしておくと、事故が起きにくくなります。
生成されるコードのイメージは次のようなものです(実際の出力は環境やライブラリのバージョンで変わるため、必ず動作確認してください)。
// logger.js(イメージ)
const pino = require('pino');
const SENSITIVE_KEYS = ['password', 'token', 'authorization', 'email', 'phone', 'card'];
const redact = (obj) => {
if (obj === null || typeof obj !== 'object') return obj;
const out = Array.isArray(obj) ? [] : {};
for (const [k, v] of Object.entries(obj)) {
if (SENSITIVE_KEYS.includes(k.toLowerCase())) {
out[k] = '[REDACTED]';
} else {
out[k] = redact(v);
}
}
return out;
};
const logger = pino({
level: process.env.NODE_ENV === 'production' ? 'info' : 'debug',
base: { service: 'order-api', env: process.env.NODE_ENV },
timestamp: pino.stdTimeFunctions.isoTime,
formatters: {
log: (obj) => redact(obj),
},
});
module.exports = logger;
実装の進め方|ロガー・メトリクス・トレースの順で入れる
一度に全部やろうとすると破綻します。私は次の順番でClaude Codeに作業を割っています。
- 構造化ロガーを作る: 上記のマスク付きロガーをまず1つ用意する。
- 相関IDのミドルウェアを入れる: リクエスト受信時に
request_idを発番し、そのリクエスト内のすべてのログに自動で付与する。 - 既存のconsole.logを段階置換する: 一気に置き換えず、エラー処理など重要な箇所から。
- メトリクスを足す: リクエスト数・エラー率・レイテンシをカウント/ヒストグラムで取る。
- トレースは必要になってから: 複数サービスをまたぐ処理が出てきたら導入を検討する。
相関IDのミドルウェアは、Claude Codeにこう頼みます。
Expressのミドルウェアを作って。受信したリクエストごとに request_id を発番し
(既存の X-Request-Id ヘッダがあればそれを優先)、そのリクエストの処理中に出る
ログ全部に request_id が自動で付くようにしたい。
AsyncLocalStorage を使ってリクエストスコープに保持し、ロガー側で
そのスコープから request_id を読んで出力に含める設計で実装して。
レスポンスヘッダにも X-Request-Id を返して。
メトリクスについては、まずは「リクエスト数」「ステータスコード別の件数」「処理時間(レイテンシ)」の3つを取れば、ほとんどの異常検知の出発点になります。Prometheus形式で/metricsエンドポイントを生やす、といった一般的な構成をClaude Codeに作らせると速いです。ただし、特定ライブラリの細かな挙動やバージョン依存の仕様は断定せず、公式ドキュメントで裏取りしてから本番に入れてください。
Claude Code自体の作業ログを残す
少し話がそれますが、「Claude Codeに何をやらせたか」自体のログも残せます。Claude CodeのHooks機能を使うと、ツール実行の前後(PreToolUse / PostToolUse)や処理完了時(Stop)などのタイミングで任意のシェルコマンドを実行できます(2026年6月時点の公式仕様)。たとえば編集系ツールの実行後に整形やログ記録を走らせる、といった使い方です。設定はsettings.jsonのhooksキーに記述します。
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit",
"hooks": [
{
"type": "command",
"command": "${CLAUDE_PROJECT_DIR}/.claude/hooks/log-edit.sh"
}
]
}
]
}
}
「どのファイルをいつ変更したか」をリポジトリ外の監査ログに残しておくと、複数人+エージェントで開発するときに後追いがしやすくなります。Hooksの詳しい使い方はClaude Codeでデプロイ・リリースを安全運用する実践ガイドでも触れています。
可視化・アラートの基本|「気づける」状態をつくる
ログとメトリクスを出しただけでは、人は見にきません。異常を向こうから知らせてくれる状態にして、はじめて監視として機能します。最初に決めるべきは「何をしきい値にして・どこに・どれだけの強さで通知するか」です。
- 何を: エラー率(例:5分間で5%超)、レイテンシ(例:p95が1秒超)、特定のERRORログの出現。
- どこに: Slackやメールなどチームがすぐ見る場所。深夜に叩き起こすものと翌朝で良いものを分ける。
- 強さ: 全部を最高優先度にしない。「即対応」と「翌営業日確認」を分けないと、通知が麻痺して誰も見なくなる。
アラート設計でClaude Codeに頼むときは、しきい値の根拠も一緒に出させると後で説明しやすくなります。
このAPIのアラート方針案を作って。前提は次の通り。
- 通知先: Slackの #alerts チャンネル(Webhook)
- 即時対応すべきもの(P1)と、翌営業日でよいもの(P2)を分けたい
次の3観点で、しきい値・観測ウィンドウ・通知先・優先度を表でまとめて。
1) エラー率 2) レイテンシ 3) 可用性(ヘルスチェック失敗)
しきい値はなぜその値かの理由も一言添えて。最初は緩めの値で提案して。
「最初は緩めに」と指定するのがコツです。いきなり厳しいしきい値にすると誤報(アラート疲れ)で運用が崩れます。運用しながら締めていく前提で始めるのが現実的です。具体的な監視SaaSやダッシュボードツールの選定は、汎用的な考え方にとどめ、特定製品の細かい挙動は公式情報を確認してください。レイテンシ悪化の原因切り分けはパフォーマンスチューニングをClaude Codeで進める実践ガイドもあわせてどうぞ。
落とし穴と対策|ここでつまずく
実際にやってみて踏んだ地雷を、❌(やりがち)⭕(こうする)の形で残しておきます。
❌ 機密情報・個人情報をログに出してしまう|⭕ 共通のマスク処理を必ず通す
これが最大かつ最悪の落とし穴です。デバッグのつもりでリクエストボディを丸ごとログに吐くと、パスワード・認証トークン・メールアドレス・カード番号がそのまま記録され、ログ基盤に残り続けます。一度出たログは収集・転送・バックアップされて回収が困難です。前述のとおり、マスク処理はロガーの内部に共通の通り道として実装し、個別呼び出しに頼らないこと。Claude Codeに新しいログ出力を書かせたら、レビュー時に「ここに機密が混ざらないか」を必ず自分の目で確認してください。
❌ ログが多すぎる/少なすぎる|⭕ レベルと出す場所を設計する
全リクエストでDEBUGを吐けば、コストもノイズも爆発し、本番でいざ見るとき肝心のERRORが埋もれます。逆に削りすぎると障害時に何も残りません。正常系はINFOで節目だけ、異常系はERRORで文脈(request_id・入力の要約・スタックの要点)をしっかり、というメリハリをつけます。「とりあえず全部出す」をClaude Codeにやらせると過剰になりがちなので、レベル方針を先に渡すのが効きます。
❌ 相関IDがなく障害を追えない|⭕ 最初からrequest_idを通す
1リクエストが複数のログ行・複数の関数にまたがると、相関IDがなければどのログが同じリクエストのものか分かりません。後付けは大変なので、ロガーと相関IDミドルウェアは初期にセットで入れておくのが正解です。
❌ 生成されたコードを無検証で本番に入れる|⭕ 人が必ずレビューする
Claude Codeは設計・実装の壁打ちに強力ですが、出力はあくまで提案です。とくにログ・監視は「何を記録し、何を記録しないか」がセキュリティに直結します。マスク漏れ、しきい値の妥当性、ライブラリのバージョン依存の挙動は、生成コードをそのまま信じず、人がレビューし、テストし、公式ドキュメントで裏取りしてから本番投入してください。エラーの再現や原因切り分けの進め方はClaude Codeでデバッグ・障害調査を効率化する実践ガイドに詳しくまとめています。
まとめと次のアクション
ログ・監視は地味ですが、いざ障害が起きたときにチームを救う「保険」です。Claude Codeを使えば、目的の言語化からログ設計、実装、アラート方針までを短時間で形にできます。ただし、機密情報の扱いと生成コードのレビューだけは絶対に手を抜かないでください。
今日からできる3アクション:
- 目的を1枚に書く: 「障害時に何を追えればいいか」をClaude Codeに整理させ、ログ設計方針の表を作る。
- マスク付きロガーを試す: 構造化+機密マスクのロガー雛形を生成させ、機密が漏れないかを自分でレビューする。
- 緩めのアラートを1本だけ入れる: エラー率のしきい値アラートをSlackに1本だけ通し、運用しながら締める。
より実践的なテクニックを体系的に学びたい方は、Claude Code 実践テクニック完全ガイドから学習順をたどるのがおすすめです。次回は、ここで作ったログ基盤の上に「エラー監視・通知(アラート)の仕組み」をもう一段くわしく組み立てる回をお届けします。
著者プロフィール
佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援に携わる。著書『AIエージェント仕事術』(SBクリエイティブ)。SoftBank IT連載を7回執筆。


