
結論:Claude Codeはバックエンド・API開発で「仕様→ルーティング→バリデーション→DBアクセス→テスト」までを一気通貫で下書きできる。鍵は、CLAUDE.mdにアーキテクチャ規約と命名規則を書き、AIに「現場のルール」を渡してから走らせることです。
- API設計:OpenAPI仕様やルーティング表を渡すと、エンドポイント・DTO・バリデーションの雛形をまとめて生成できる。
- DB・認証・テスト:ORMモデル定義、JWT認証ミドルウェア、ユニット/統合テストまで、既存パターンに合わせた下書きが速い。
- レビュー前提:生成コードは必ず人がレビュー・テスト・セキュリティ確認する。特に認証・認可・機密情報の扱いはAI任せにしない。
対象読者:Web API・バックエンドを実装するエンジニア/テックリード(Node.js・Python・Go・Java など。Claude Codeを試したことがある〜中級者)。
今日やること:自分のリポジトリのルートに、フレームワーク・命名規則・エラーレスポンス形式を書いた最小のCLAUDE.mdを置いてから、1本のエンドポイント実装をClaude Codeに頼んでみる。
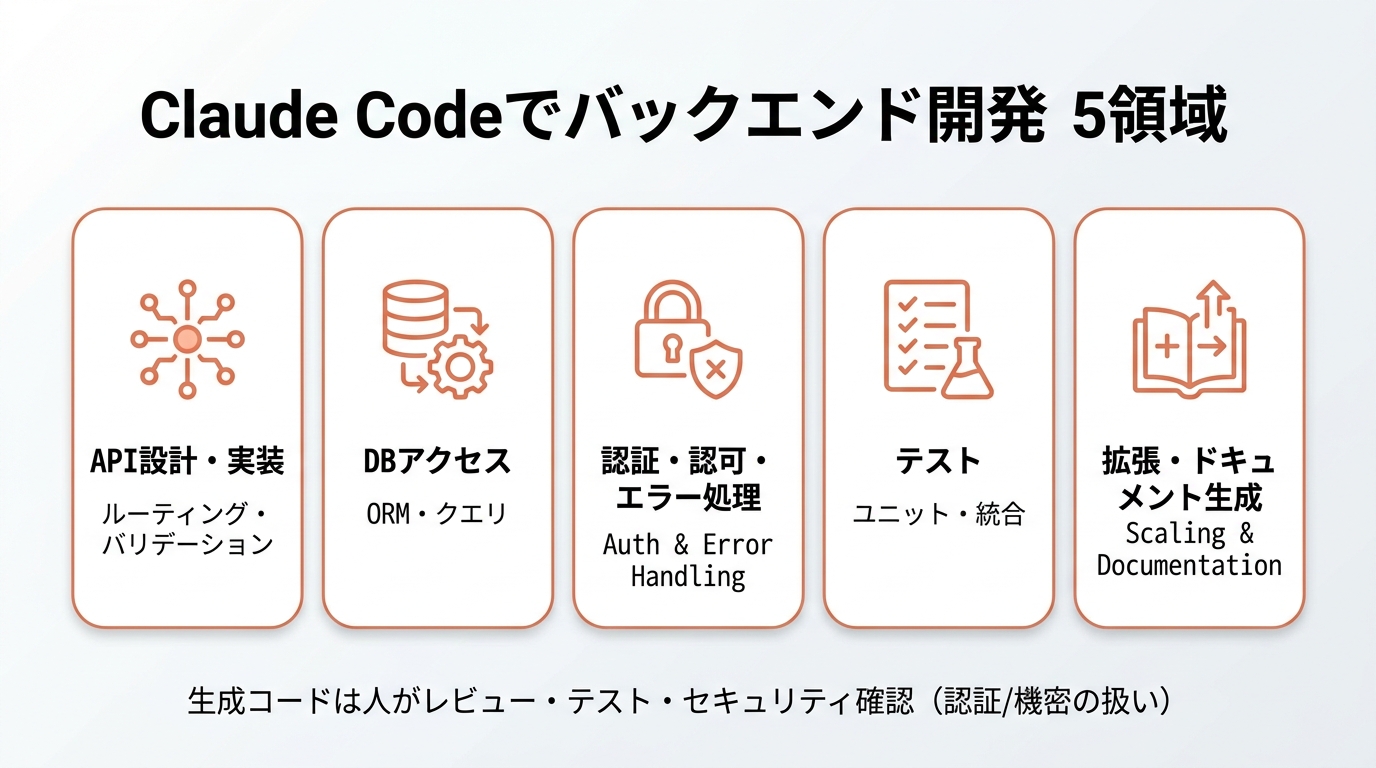
「Claude Codeってフロントのコンポーネント生成は速いけど、バックエンドのAPI開発でも本当に使えるの?」——これは実装の相談でいちばんよく聞かれる質問のひとつです。結論から言うと、バックエンドこそ相性がいい領域です。API開発は「仕様が決まっている」「規約がある」「テストで挙動を固定できる」という、AIが力を発揮しやすい条件がそろっているからです。
この記事では、バックエンド開発者がClaude Codeを使って、API設計・DBアクセス・認証/認可・テスト・既存APIの拡張を効率化する実践ワークフローを、コピペで試せる指示例(プロンプト)とコード例つきで解説します。動作確認は2026年6月時点のClaude Code(コマンド `claude`)を前提にしています。Claude Code固有の機能やコマンド名は、変更され得るため公式ドキュメントで最新の挙動を確認してください。
まずCLAUDE.mdに「バックエンドの規約」を書く
バックエンドのコードは、命名規則・レイヤー構成・エラーレスポンスの形・ログの出し方など、プロジェクト固有の約束事が多い領域です。これをAIに毎回プロンプトで説明していたら効率が悪い。そこで最初にやるべきは、リポジトリのルートに置く CLAUDE.md(プロジェクトメモリ)にアーキテクチャ規約を書くことです。Claude Codeはセッション開始時にこのファイルを自動で読み込みます(公式: Memory management)。
たとえば、レイヤードアーキテクチャのNode.js/TypeScript APIなら、こんな内容を書いておきます。
# プロジェクト規約(バックエンドAPI)
## アーキテクチャ
- レイヤー構成: routes → controllers → services → repositories
- controllers はHTTP処理のみ。ビジネスロジックは services に置く
- DBアクセスは repositories に集約し、services から直接ORMを呼ばない
## 命名規則
- ファイル: kebab-case(例: user-profile.service.ts)
- 関数: camelCase / 型・クラス: PascalCase
- DTOは `Xxx Request` / `Xxx Response` で命名
## エラーレスポンス
- 形式は必ず `{ "error": { "code": string, "message": string } }`
- HTTPステータスは 400/401/403/404/409/422/500 のみ使う
- 例外は AppError を throw し、エラーハンドラで整形する
## バリデーション
- 入力検証は zod スキーマで行い、controller の入口で実行する
## テスト
- ユニットテストは Vitest、統合テストは supertest
- 1エンドポイントにつき正常系1 + 異常系2以上
この一手間が効きます。規約を書いておくと、後段で「ユーザー登録APIを実装して」と頼むだけで、AIはレイヤー分割・命名・エラー形式・バリデーション方針を踏まえた下書きを出してくれる。逆にここを書かないと、controllerにビジネスロジックを直書きしたり、エラー形式がバラバラなコードが出てきて、レビューで直す量が増えます。CLAUDE.mdの設計・運用は奥が深いので、CLAUDE.md設計・運用ガイドもあわせて読んでみてください。
正直にお伝えすると、CLAUDE.mdは「最初から完璧」を目指す必要はありません。AIが規約から外れたコードを出したら、その都度ルールを1行追記していく運用が現実的です。育てるドキュメントとして扱うのがコツです。
API設計とエンドポイント実装:仕様からルーティングを起こす
API開発で最初の山場は、仕様からルーティング・入力検証・DTOの雛形を起こすところです。ここはClaude Codeが特に速い。要件や既存のOpenAPI仕様を渡して、エンドポイントの骨格をまとめて生成させます。
指示例(プロンプト):
新しいエンドポイント POST /api/v1/users を実装してください。
要件:
- リクエスト: { email, password, displayName }
- email形式チェック、passwordは8文字以上、displayNameは1〜50文字
- 既存emailと重複したら 409 を返す
- 成功時は201で { id, email, displayName, createdAt } を返す(passwordは返さない)
CLAUDE.mdの規約(レイヤー構成・zodバリデーション・エラー形式)に従ってください。
不足している情報があれば、最初に質問してから作業を開始してください。
仮定した点は必ず「仮定」と明記してください。このとき大事なのが「不足情報は質問して」「仮定は明記して」の2行です。これを入れておくと、AIが勝手に仕様を埋めて進むのを防げます。たとえば「emailの一意性チェックはDBのユニーク制約に任せるか、事前にSELECTで確認するか」のような判断を、黙って決めずに確認してくれるようになります。
生成されるコードのイメージはこんな具合です(Express + zod の例)。
// schemas/user.schema.ts
import { z } from "zod";
export const createUserRequest = z.object({
email: z.string().email(),
password: z.string().min(8),
displayName: z.string().min(1).max(50),
});
export type CreateUserRequest = z.infer<typeof createUserRequest>;
// controllers/user.controller.ts
export async function createUser(req: Request, res: Response) {
const body = createUserRequest.parse(req.body); // 入口で検証
const user = await userService.register(body);
res.status(201).json(user);
}ポイントは、AIに「全部一気に書かせない」ことです。まずスキーマとcontrollerの骨格を出させ、内容を確認してからservice・repositoryへ進む。段階的に頼むほうが、各ステップでレビューでき、最終的な品質が上がります。大きな変更になりそうなときは、Plan Mode実践ガイドで紹介している計画モードを使い、コードを書く前に実装方針をレビューする流れが安全です。
DBアクセスとモデル定義:ORM・クエリを規約に沿わせる
次はDBアクセス層です。ORMのモデル定義やマイグレーション、クエリの実装は、パターンが決まっていればAIが量産しやすい部分です。ただし、ここはバグると本番データに影響する領域なので、生成物のレビューは特に丁寧にやります。
指示例(プロンプト):
users テーブルに対応するORMモデルとrepositoryを実装してください。
- カラム: id (uuid, PK), email (unique, not null),
password_hash (not null), display_name, created_at, updated_at
- repository に findByEmail / create / updateDisplayName を実装
- SQLインジェクション対策のため、生SQLを書く場合はパラメータバインドを必須にする
- N+1にならないよう、関連取得はまとめて行う
既存の repositories/ のコードスタイルに合わせてください。「既存のコードスタイルに合わせて」と添えるのが効きます。Claude Codeはリポジトリ内の既存ファイルを読んでから書くので、すでにあるrepositoryの書き方(戻り値の型、エラー処理、トランザクションの張り方)に寄せてくれます。新規プロジェクトでスタイルが固まっていない場合は、参考にしたいファイルを1つ指定するとブレが減ります。
正直に言うと、DB周りはAIが間違えやすいポイントもあります。よく見かけるのは次のあたりです。
- マイグレーションのロールバック(down)を書き忘れる
- インデックスの提案が抜ける(emailにユニークインデックスは付いても、検索頻度の高いカラムが見落とされる)
- トランザクション境界が曖昧(複数テーブル更新なのにトランザクションで囲わない)
これらは「マイグレーションのup/down両方を書いて」「この処理は1トランザクションにまとめて」と明示的に指示すれば防げます。スキーマ変更のレビューを標準化したいときは、API仕様変更レビューの標準化の考え方が、DBスキーマ差分のチェックにも応用できます。
認証・認可・エラーハンドリング:ここは特に人がレビューする
認証(誰なのか)・認可(何をしていいか)・エラーハンドリングは、バックエンドのセキュリティの中核です。Claude Codeで実装の下書きはできますが、この領域こそ生成コードを鵜呑みにせず、人がセキュリティ観点でレビューすることを前提にしてください。トークンの検証漏れ、認可チェックの抜け、エラーメッセージへの機密情報の混入などは、AIが見落とすことがあります。
指示例(プロンプト):
JWT認証ミドルウェアと、ロールベースの認可チェックを実装してください。
- Authorization: Bearer <token> を検証し、無効なら401を返す
- トークンの署名検証・有効期限チェックを必ず行う
- req.user に { id, role } を載せる
- requireRole("admin") のような認可ミドルウェアを用意する
- 認可に失敗したら403を返す
重要: 秘密鍵やトークンはコードにハードコードせず、環境変数から読む前提で。
エラーレスポンスに内部情報(スタックトレース・SQL・トークン)を含めないでください。最後の2行を必ず入れてください。秘密情報のハードコード禁止と、エラーレスポンスに内部情報を出さない指示は、セキュリティの基本です。それでも生成後には、人の目で次を確認します。
- 署名検証アルゴリズムの固定:JWTの
algを検証時に明示的に指定しているか(noneやアルゴリズム混同攻撃への対策) - 認可の網羅:「ログインしていればOK」になっていないか。リソースの所有者チェック(自分のデータだけ操作できる)が入っているか
- 機密情報の非露出:ログやレスポンスにトークン・パスワード・個人情報が出ていないか
エラーハンドリングは、CLAUDE.mdに書いたエラーレスポンス形式に沿って一元化させるのがおすすめです。各controllerでtry/catchを散らすのではなく、共通のエラーハンドラに集約させると、形式の一貫性が保てます。なお、本番運用での認証・認可・データの扱いは、所属組織のセキュリティ規程・コンプライアンスに従ってください。AIは補助ツールであり、最終的な安全性の判断者ではありません。
テスト:ユニット・統合テストを自動生成して挙動を固定する
API開発でClaude Codeがいちばん効くのは、実はテスト生成かもしれません。「実装したエンドポイントのテストを書いて」と頼むだけで、正常系・異常系・境界値のテストケースを下書きしてくれます。テストがあれば、その後にAIへリファクタを頼んでも、挙動が変わっていないかをすぐ確認できます。
指示例(プロンプト):
POST /api/v1/users の統合テストを supertest で書いてください。
カバーするケース:
1. 正常系: 有効な入力で201、レスポンスにpasswordが含まれないこと
2. 異常系: emailが不正な形式で422
3. 異常系: passwordが8文字未満で422
4. 異常系: 既存emailと重複で409
テストデータは各テストで独立させ、実行順に依存しないようにしてください。「実行順に依存しないように」と添えるのが地味に重要です。AIが生成するテストは、たまにグローバルな状態を共有して、単体では通るのに全体実行で落ちることがあります。独立性を最初に指示しておくと、この手のflakyなテストを減らせます。
テスト駆動でAPIを作るなら、先にテストを書いてから実装をClaude Codeに頼む流れも有効です。「このテストを通す最小の実装をして」と頼むと、AIは仕様(=テスト)に合わせてコードを書きます。テスト自動生成・TDDの詳しいやり方は、テスト自動生成・TDD実践ガイドにまとめています。
もうひとつの使い方が、CI/CDへの組み込みです。Pull Requestごとにテストとリンターを走らせ、失敗時にClaude Codeで原因を切り分ける運用にすると、レビュー負荷が下がります。CI/CDの自動構築はCI/CDパイプライン自動構築ガイドを参照してください。
既存APIの拡張・リファクタ・ドキュメント生成
ゼロから作るより、既存APIを拡張・リファクタする場面のほうが実務では多いはずです。Claude Codeはリポジトリ全体を読んで文脈を踏まえられるので、こうした作業でも力を発揮します。
既存エンドポイントへのフィールド追加(指示例):
GET /api/v1/users/:id のレスポンスに `lastLoginAt` を追加してください。
- DBにカラムを追加するマイグレーション(up/down両方)を作成
- ORMモデル・DTO・レスポンス整形・テストを横断して更新
- 既存のテストが壊れていないか確認してください
- 後方互換を壊さないこと(既存フィールドは変更しない)「横断して更新」「後方互換を壊さない」を明示すると、モデル・DTO・テストの更新漏れを防げます。フィールドを1つ足すだけでも、関連ファイルが5〜6個に及ぶことはよくあります。AIに横断更新を任せると、この見落としが減ります。
リファクタ(指示例):
controllers/order.controller.ts にビジネスロジックが直書きされています。
CLAUDE.mdの規約どおり、ロジックを services/order.service.ts に移してください。
- 振る舞いは一切変えないこと
- 既存のテストがすべて通る状態を維持してください
- 変更後、何をどこに移したかを要約してくださいリファクタで重要なのは「振る舞いを変えない」と「テストが通る状態を維持」の2点です。テストがある状態でリファクタを頼めば、安全網が効きます。逆にテストがない箇所のリファクタは、先にテストを書かせてから着手するのが鉄則です。大規模なレガシー移行を扱う場合は、レガシーコード移行・大規模リファクタガイドの段階的アプローチが参考になります。
APIドキュメント生成:実装からOpenAPI(Swagger)仕様を起こすのもClaude Codeの得意分野です。「routes/ 配下の全エンドポイントからOpenAPI 3.1のYAMLを生成して。各エンドポイントのリクエスト/レスポンススキーマ、エラーレスポンスも含めて」と頼むと、ドキュメントの下書きが手に入ります。ただし生成された仕様が実装と一致しているかは、必ず人が突き合わせて確認してください。
【要注意】よくある失敗パターンと回避策
バックエンド開発でClaude Codeを使うとき、つまずきやすいポイントを整理します。
失敗1:規約を渡さずに「いい感じのAPI」を頼む
❌「ユーザー管理のAPIをいい感じに作って」
⭕「CLAUDE.mdの規約(レイヤー構成・エラー形式・命名)に従ってPOST /api/v1/usersを実装して」
なぜ重要か:「いい感じ」の定義はAIにはありません。規約を渡さないと、プロジェクトのスタイルから外れたコードが出て、レビューで直す量が増えます。最初にCLAUDE.mdを整えるのが、結果的にいちばんの近道です。
失敗2:認証・認可のコードをレビューせずにマージする
❌ 生成されたJWT検証ミドルウェアをそのまま本番へ
⭕ 署名検証・有効期限・アルゴリズム固定・所有者チェックを人が確認してからマージ
なぜ重要か:認証・認可はセキュリティの中核です。AIは「動くコード」は書けても、攻撃面(アルゴリズム混同、認可漏れ、トークン露出)を見落とすことがあります。ここだけは必ず人がセキュリティ観点でレビューしてください。
失敗3:テストなしでリファクタを頼む
❌ テストがない状態で「このコードをきれいにして」
⭕ 先にテストを書かせ、テストが通る状態を維持しながらリファクタする
なぜ重要か:テストという安全網がないと、リファクタで挙動が変わっても気づけません。AIにリファクタを任せるなら、まず挙動を固定するテストを用意するのが先決です。
失敗4:機密情報・本番データを前提にした指示を出す
❌ 実際のAPIキーや本番接続文字列をプロンプトに貼る
⭕ 秘密情報は環境変数から読む前提で書かせ、サンプル値はダミーにする
なぜ重要か:機密情報の扱いは慎重に。秘密鍵・トークン・個人情報はプロンプトに含めず、コードにもハードコードさせない。環境変数経由を徹底してください。
段階的に導入するロードマップ
いきなり全工程をAIに任せるのではなく、効果が見えやすいところから段階的に広げるのがおすすめです。
フェーズ1(最初の1〜2週間):既存コードのテスト生成から始める。リスクが低く、効果がすぐ実感できます。同時にCLAUDE.mdの初版を作り、規約を書き出します。
フェーズ2(次の数週間):新規エンドポイントの実装をClaude Codeに任せる。仕様→スキーマ→controller→service→テストの順に、段階的にレビューしながら進めます。Plan Modeで実装方針を先にレビューする習慣をつけます。
フェーズ3(定着段階):既存APIの拡張・リファクタ・ドキュメント生成へ広げる。CI/CDにテストとレビューを組み込み、Pull Requestごとに品質を担保する運用にします。複数の作業を並行させたいときは、サブエージェント並列開発の手法が効きます。
よくある質問(FAQ)
Q1. Claude Codeはどのバックエンド言語・フレームワークに対応していますか?
Claude Codeは特定言語専用のツールではなく、リポジトリのコードを読んで作業するエージェントなので、Node.js・Python・Go・Java・Ruby・PHPなど主要なバックエンド言語で利用できます。フレームワーク固有の規約はCLAUDE.mdに書いて渡すのが効果的です。詳細は公式ドキュメントを確認してください。
Q2. 生成されたAPIコードはそのまま本番で使えますか?
そのまま使うのは推奨しません。Claude Codeの出力は「下書き」と捉え、人によるコードレビュー・テスト実行・セキュリティ確認を経てから本番に入れてください。特に認証・認可・機密情報・DB変更を含む箇所は、必ず人が最終判断します。
Q3. CLAUDE.mdには何を書けばいいですか?
バックエンドなら、アーキテクチャ(レイヤー構成)・命名規則・エラーレスポンス形式・バリデーション方針・テストの書き方・使ってよい/避けるべきライブラリなどを書きます。最初から完璧を目指さず、AIが規約から外れた都度1行ずつ追記して育てるのが現実的です。詳しくはCLAUDE.md設計・運用ガイドを参照してください。
Q4. 機密情報をどう扱えばいいですか?
APIキー・秘密鍵・本番接続文字列・個人情報はプロンプトに貼らず、コードにもハードコードさせないでください。環境変数や秘密管理サービスから読む前提でコードを書かせます。本番運用では所属組織のセキュリティ規程・コンプライアンスに従ってください。
Q5. 大きなAPI開発をどう分割して頼めばいいですか?
一度に全部を頼まず、「スキーマ→controller→service→repository→テスト」のように段階分割します。各ステップでレビューと軌道修正ができ、品質が安定します。大きな変更はPlan Modeで方針を先にレビューし、独立した作業はサブエージェントで並列化すると効率的です。
まとめ:今日から始める3つのアクション
Claude Codeはバックエンド・API開発の「下書きエンジン」として、仕様からの実装・テスト・拡張を大きく効率化します。ただし主役はあくまでエンジニアで、AIの出力をレビュー・テスト・セキュリティ確認するプロセスが品質を決めます。今日から試せることを3つ挙げます。
- CLAUDE.mdを置く:リポジトリのルートに、フレームワーク・命名規則・エラー形式を書いた最小のCLAUDE.mdを作る。
- テスト生成から始める:既存エンドポイント1本のテストをClaude Codeに書かせ、効果を体感する。
- 1本のエンドポイントを段階実装:新規エンドポイントを、スキーマ→controller→service→テストの順にレビューしながら実装してみる。
バックエンド開発でのClaude Code活用は、規約づくりとレビュー体制さえ整えば、チーム全体の開発速度を底上げできます。まずは小さく試して、自分のプロジェクトに合うワークフローを見つけてください。さらに踏み込んだ実践テクニックはClaude Code 実践テクニック完全ガイドにまとめています。
著者プロフィール
佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援を手がける。著書『AIエージェント仕事術』(SBクリエイティブ)。SoftBank IT連載を執筆。


