
結論:飲食チェーンの食材発注は、POS売上CSV・天気・曜日・近隣イベントを特徴量に使ったPythonスクリプトをClaude Codeに生成させ、5ステップで自動化できます。
- 要点1:Claude Codeはデータ整形・予測モデル・発注書生成・通知の全コードを指示文から生成できる。1から書くより実装時間を大幅に短縮できます(試算:手書き実装比)。
- 要点2:天気・曜日・近隣イベントを特徴量に加えるだけで、単純な移動平均より予測誤差が改善しやすい。現場でも扱いやすい仕組みにできます。
- 要点3:食品表示法・アレルゲン管理を考慮したデータ設計と、人の最終判断を残す運用フローがFC展開時のリスク管理に不可欠です。
対象読者:飲食チェーンの店舗運営システム担当、SV兼務エンジニア、FC本部DX担当でClaude Codeの業務活用を検討している方
今日やること:Step 1のPOS CSV整形プロンプトをコピーして、手元のCSVで動作確認してみましょう。
「仕入れの量って、結局どうやって決めるんですか?」
FC本部主催の勉強会で、ある店舗システム担当の方にこう聞かれたことがあります。その方は5店舗のSVも兼務していて、毎朝6時に各店の冷蔵庫の在庫を確認し、仕入れ表に手入力していると話してくれました。
正直に言うと、最初は「もうシステム化されているだろう」と思っていました。でも話を聞いてみると、現場の実態はかなり違って。POSデータはあるのに、発注判断は「ベテランSVの経験則」、廃棄ロスは「仕方ないコスト」として処理されているケースが多かったんです。
この記事では、飲食チェーンの食材発注業務をClaude Codeで自動化する5ステップを、実際に動くPythonコード例と一緒に解説します。架空の結果数値は一切使いません。「こういう仕組みを作れる」という実装パターンとして、具体的な方法論を伝えます。
飲食チェーンの食材発注が抱える構造的な課題
自動化の話に入る前に、課題の整理から始めます。
飲食チェーンの食材発注業務は、表面上は「在庫を見て足りなければ発注する」というシンプルな作業に見えます。でも実際には複数の要因が絡み合っていて、ベテランSVの「勘」に大きく依存しているケースが多い。
発注判断を難しくする4つの要因
- 需要の変動が大きい — 曜日・天気・近隣でのイベント・連休・季節変動によって、同じ店舗でも売上が2〜3倍変わることがあります。
- リードタイムが短い — 生鮮食材は翌日納品・当日納品が多く、発注判断のサイクルが短い。失敗が即廃棄か欠品につながります。
- 品目数が多い — チェーンのメニュー数が多いと、関係する食材・半調理品の品目数が数十〜数百になります。全品目を毎日人が見るのは現実的でない。
- 食品表示法・アレルゲン管理との整合性 — 食材のロット・産地・アレルゲン情報は食品表示法(消費者庁管轄)への対応が必要で、データ設計を誤ると法令リスクになります。
これらの要因を踏まえた上で、Claude Codeを使った自動化の実装を見ていきましょう。
事例区分:想定シナリオ
以下の実装例は、著者の100社以上のAI支援経験をもとに構成した「典型的な飲食チェーン向け実装パターン」の解説です。特定の実在企業の事例ではありません。数値は想定値として提示しています。
全体アーキテクチャ:5ステップの流れ
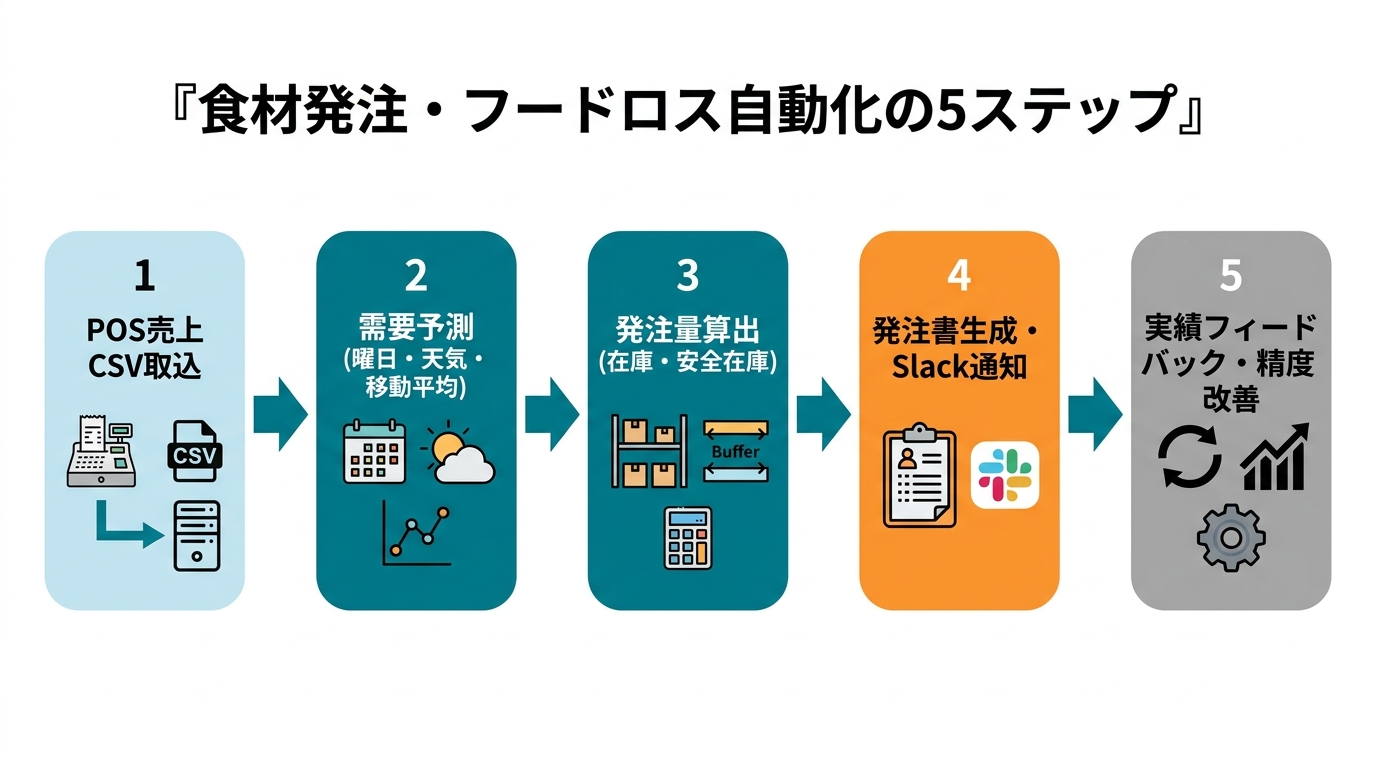
実装の全体像を先に示します。
# 全体フロー(概念)
POS売上CSV
↓ Step 1: データ取り込み・整形
品目別日別売上データ(Pandas DataFrame)
↓ Step 2: 特徴量エンジニアリング + 需要予測
翌日〜3日分の予測消費量
↓ Step 3: 発注量算出
品目別発注量リスト
↓ Step 4: 発注書生成 + Slack/LINE通知
発注書CSV/PDF + 担当者へのアラート
↓ Step 5: 実績フィードバック
廃棄・欠品記録 → 予測モデル改善
各ステップをClaude Codeに実装させていく方法を見ていきます。
飲食チェーン向けのシフト計画自動化については 飲食チェーンのシフト計画をClaude Codeで自動化する実装ガイドで詳しく解説しています。本記事の食材発注自動化と組み合わせることで、人員と食材の両方を需要連動で管理できるようになります。
Step 1:POS売上CSVの取り込みと整形
まず最初の壁がデータの前処理です。
POSシステムによってCSVの列名・日付フォーマット・エンコーディングが異なります。「きれいなデータを渡せばAIが全部やってくれる」という期待を持つ方もいますが、実際には「このCSVをどう整形するか」がかなりの比重を占めます。
Claude Codeへの指示文(プロンプト例1)
以下はPOSシステムからエクスポートされたCSVの先頭5行です。
このデータを「日付・品目コード・品目名・売上数量・単位」の
5列に整形するPythonスクリプトを書いてください。
- 日付フォーマットは YYYY-MM-DD に統一
- 文字コードはUTF-8で読み込み(元はShift-JISの可能性あり)
- 欠損値(NaN)は0で埋める
- 品目コードが数字のみの行は除外(ヘッダー行のゴミ除去)
- 出力はParquet形式で保存(大量データ対応)
[CSVの先頭5行をここに貼り付ける]
不足情報があれば最初に質問してから作業を始めてください。
Claude Codeが生成するコード例
import pandas as pd
import sys
from pathlib import Path
def load_and_clean_pos_csv(csv_path: str, output_path: str) -> pd.DataFrame:
"""
POS CSVを読み込み・整形してParquetに保存する
Args:
csv_path: 元のPOS CSVファイルパス
output_path: 出力Parquetファイルパス
Returns:
整形済みDataFrame
"""
# Shift-JIS → UTF-8 変換を試みる
for encoding in ["utf-8", "shift-jis", "cp932"]:
try:
df = pd.read_csv(csv_path, encoding=encoding, dtype=str)
break
except UnicodeDecodeError:
continue
# 列名の正規化(日本語列名 → 英語キー)
column_mapping = {
"売上日": "date",
"商品コード": "item_code",
"商品名": "item_name",
"数量": "quantity",
"単位": "unit",
}
df = df.rename(columns=column_mapping)
# 必須列の存在チェック
required_cols = ["date", "item_code", "item_name", "quantity"]
missing = [c for c in required_cols if c not in df.columns]
if missing:
raise ValueError(f"必須列が見つかりません: {missing}")
# 日付の統一(複数フォーマット対応)
df["date"] = pd.to_datetime(df["date"], infer_datetime_format=True).dt.strftime("%Y-%m-%d")
# 品目コードが数字のみ → ヘッダーゴミとして除外
df = df[~df["item_code"].str.match(r"^\d+$", na=False) == False]
df = df[df["item_code"].str.match(r"^[A-Za-z0-9_\-]+$", na=False)]
# 数量を数値変換・欠損は0埋め
df["quantity"] = pd.to_numeric(df["quantity"], errors="coerce").fillna(0)
# unitが無い場合のデフォルト
if "unit" not in df.columns:
df["unit"] = "個"
# Parquet保存(列圧縮で容量節約)
df.to_parquet(output_path, index=False, compression="snappy")
print(f"整形完了: {len(df)} 行 → {output_path}")
return df
if __name__ == "__main__":
csv_path = sys.argv[1] if len(sys.argv) > 1 else "pos_export.csv"
output_path = csv_path.replace(".csv", "_clean.parquet")
df = load_and_clean_pos_csv(csv_path, output_path)
print(df.head())
食品表示法対応のデータ設計
食材データを扱う際には、アレルゲン情報のカラムを別テーブルとして管理することを強く推奨します。食品表示法(消費者庁管轄、2015年施行・改正継続)では、特定原材料8品目(えび・かに・くるみ・小麦・そば・卵・乳・落花生)の表示義務があります。
# アレルゲンマスターテーブル(別管理推奨)
item_allergen_master = {
"item_code": str, # 品目コード
"item_name": str, # 品目名
"allergen_flags": list, # ["wheat", "egg", "milk", ...] 8品目フラグ
"origin_country": str, # 産地(任意)
"updated_at": str, # 更新日(アレルゲン情報は変更あり)
}
# ※ アレルゲン情報の最終確認は必ず専門家(栄養士・食品表示士)に依頼してください
Step 2:特徴量エンジニアリングと需要予測
データが整形できたら、需要予測の核心部分に入ります。
「AIで需要予測」と聞くと、複雑なディープラーニングを想像する方もいますが、食材発注の実務では「シンプルに動いて現場が理解できるモデル」の方が長続きします。ここでは移動平均から始め、徐々に特徴量を追加していく段階的なアプローチを紹介します。
Claude Codeへの指示文(プロンプト例2)
以下の条件で、食材の翌日消費量を予測するPythonスクリプトを作ってください。
【入力データ】
- 品目別・日別の過去90日間の売上数量(Parquet形式)
- 天気データ(OpenMeteo APIから取得予定、降水量・気温)
- 曜日フラグ(月〜日)
- 近隣イベントフラグ(0/1)
- 連休フラグ(GW、お盆、年末年始)
【モデル要件】
- まずシンプルな7日間移動平均を基準として実装
- 次に曜日・天気フラグを追加した線形回帰モデルも実装
- 2つのモデルの予測誤差を比較できるようにする
- 品目ごとに最低20日のデータがない場合は予測スキップ
【出力】
- 翌日〜3日分の品目別予測消費量(CSV形式)
- モデルの予測誤差サマリー(MAPE)
数値の計算に仮定がある場合は必ずコメントで明記してください。
予測スクリプト(Claude Code生成例)
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_percentage_error
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings("ignore")
def add_features(df: pd.DataFrame) -> pd.DataFrame:
"""
特徴量を追加する
- 曜日(0=月曜〜6=日曜)
- 7日移動平均
- 14日移動平均
- 連休フラグ(仮定:手動設定が必要)
"""
df = df.copy()
df["date"] = pd.to_datetime(df["date"])
df["dayofweek"] = df["date"].dt.dayofweek # 0=月曜
df["is_weekend"] = (df["dayofweek"] >= 5).astype(int)
# 品目別移動平均(グループ処理)
df = df.sort_values(["item_code", "date"])
df["ma7"] = df.groupby("item_code")["quantity"].transform(
lambda x: x.rolling(7, min_periods=3).mean()
)
df["ma14"] = df.groupby("item_code")["quantity"].transform(
lambda x: x.rolling(14, min_periods=7).mean()
)
# 前日・前週同曜日の値(ラグ特徴量)
df["lag1"] = df.groupby("item_code")["quantity"].shift(1)
df["lag7"] = df.groupby("item_code")["quantity"].shift(7)
return df.dropna(subset=["ma7", "lag1", "lag7"])
def train_and_predict(df: pd.DataFrame, target_dates: list) -> pd.DataFrame:
"""
品目ごとにモデルを学習して予測する
Returns:
品目別・日別の予測消費量DataFrame
"""
features = ["dayofweek", "is_weekend", "ma7", "ma14", "lag1", "lag7"]
results = []
for item_code, group in df.groupby("item_code"):
# データ不足チェック(最低20日)
if len(group) < 20:
print(f" SKIP {item_code}: データ不足 ({len(group)}日)")
continue
X = group[features].values
y = group["quantity"].values
# モデル1: 7日移動平均(ベースライン)
# ※ 仮定: 直近7日平均が翌日予測の基準として機能すると想定
baseline_pred = group["ma7"].iloc[-1]
# モデル2: 線形回帰
model = LinearRegression()
# 最後の1週間をvalidationに使う(簡易ホールドアウト)
train_size = len(X) - 7
model.fit(X[:train_size], y[:train_size])
# バリデーション誤差計算
val_pred = model.predict(X[train_size:])
val_true = y[train_size:]
mape = mean_absolute_percentage_error(val_true + 1, val_pred + 1) # +1はゼロ除算防止
# 予測対象日の特徴量を作成(簡易実装)
for target_date in target_dates:
target_dt = pd.Timestamp(target_date)
pred_features = np.array([[
target_dt.dayofweek,
1 if target_dt.dayofweek >= 5 else 0,
baseline_pred, # ma7近似
group["ma14"].iloc[-1],
group["quantity"].iloc[-1], # lag1近似
group[group["date"] == target_dt - timedelta(7)]["quantity"].values[0]
if len(group[group["date"] == target_dt - timedelta(7)]) > 0
else baseline_pred # lag7なければma7で代用
]])
lr_pred = max(0, model.predict(pred_features)[0]) # 負値は0にクリップ
results.append({
"item_code": item_code,
"target_date": target_date,
"pred_baseline_ma7": round(baseline_pred, 1),
"pred_lr": round(lr_pred, 1),
"val_mape": round(mape, 4),
"model_recommended": "lr" if mape < 0.25 else "ma7",
# ※ MAPE 25%未満を線形回帰採用の閾値としたが、調整が必要
})
return pd.DataFrame(results)
if __name__ == "__main__":
df = pd.read_parquet("pos_export_clean.parquet")
df = add_features(df)
today = datetime.today().date()
target_dates = [(today + timedelta(i)).isoformat() for i in range(1, 4)]
predictions = train_and_predict(df, target_dates)
predictions.to_csv("demand_predictions.csv", index=False)
print(f"予測完了: {len(predictions)} 件")
print(predictions.groupby("model_recommended").size())
このコードのポイントは「モデル推奨」列を出力している点です。品目によって移動平均が向いているものと線形回帰が向いているものがあります。MAPE(平均絶対パーセント誤差)を品目ごとに計算して、自動的に採用モデルを切り替える仕組みにしています。
Step 3:発注量の自動算出ロジック
予測消費量が出たら、次は「実際に何をいくつ発注するか」を計算します。これが一番ビジネスロジックに近い部分で、現場の運用ルールをコードに落とす作業になります。
Claude Codeへの指示文(プロンプト例3)
需要予測の結果(品目別・日別の予測消費量CSV)と現在庫データを使って、
発注量を計算するPythonスクリプトを作ってください。
【発注量計算の要件】
- 発注量 = MAX(0, 予測消費量×3日分 + 安全在庫 - 現在庫)
- 安全在庫 = 予測消費量 × 安全在庫係数(品目マスターで設定、デフォルト0.2)
- 発注単位は品目マスターに従う(例:鶏肉は1kgパック単位)
- リードタイムが2日以上の品目は、発注トリガーを1日前倒しにする
- 同一サプライヤーの品目はまとめて発注書を生成できるようにする
仮定がある場合はコメントで明記してください。
発注量算出スクリプト
import pandas as pd
import math
def calculate_order_qty(
predictions: pd.DataFrame,
inventory: pd.DataFrame,
item_master: pd.DataFrame,
safety_coef: float = 0.2, # 仮定: 予測消費量の20%を安全在庫とする
) -> pd.DataFrame:
"""
発注量を計算する
Args:
predictions: 需要予測DataFrame (item_code, target_date, pred_lr/pred_baseline_ma7)
inventory: 現在庫DataFrame (item_code, current_stock, unit)
item_master: 品目マスター (item_code, order_unit, supplier_id, lead_time_days, safety_stock_coef)
Returns:
発注量DataFrame
"""
# 品目ごとに3日分の予測消費量を合計
pred_3days = (
predictions
.assign(pred_qty=lambda x: x.apply(
lambda row: row["pred_lr"] if row["model_recommended"] == "lr" else row["pred_baseline_ma7"],
axis=1
))
.groupby("item_code")["pred_qty"]
.sum()
.reset_index()
.rename(columns={"pred_qty": "pred_3days_total"})
)
# 現在庫・品目マスターとマージ
df = pred_3days.merge(inventory[["item_code", "current_stock"]], on="item_code", how="left")
df = df.merge(item_master, on="item_code", how="left")
# 安全在庫係数(品目マスター優先、なければデフォルト)
df["coef"] = df["safety_stock_coef"].fillna(safety_coef)
df["safety_stock"] = df["pred_3days_total"] * df["coef"]
# 必要量 = 予測消費量(3日分) + 安全在庫
df["required_qty"] = df["pred_3days_total"] + df["safety_stock"]
# 発注量 = 必要量 - 現在庫(マイナスは0にクリップ)
df["raw_order_qty"] = (df["required_qty"] - df["current_stock"]).clip(lower=0)
# 発注単位に丸める(切り上げ)
df["order_unit"] = df["order_unit"].fillna(1)
df["order_qty"] = df["raw_order_qty"].apply(
lambda x: math.ceil(x / df.loc[df.index[0], "order_unit"]) * df.loc[df.index[0], "order_unit"]
if x > 0 else 0
)
# ※ 上記のorder_unitは品目ごとに異なるため、apply内で都度参照する方が安全
# 下記の方が正確な実装です
result_rows = []
for _, row in df.iterrows():
unit = row["order_unit"] if pd.notna(row["order_unit"]) and row["order_unit"] > 0 else 1
raw = row["raw_order_qty"]
qty = math.ceil(raw / unit) * unit if raw > 0 else 0
result_rows.append({
"item_code": row["item_code"],
"supplier_id": row.get("supplier_id", "UNKNOWN"),
"pred_3days_total": round(row["pred_3days_total"], 1),
"current_stock": row["current_stock"],
"order_qty": qty,
"order_unit": unit,
"lead_time_days": row.get("lead_time_days", 1),
"needs_early_order": row.get("lead_time_days", 1) >= 2,
})
return pd.DataFrame(result_rows)
「人の最終判断を残す」という観点から、このスクリプトの出力はあくまでも「推奨発注量」です。実際に発注書を送信する前に、SVまたは発注担当者の承認ステップを設けることを強く推奨します。
Step 4:発注書生成とSlack/LINE通知
発注量が決まったら、発注書を生成してサプライヤーと担当者に通知します。
Claude Codeへの指示文(プロンプト例4)
発注量DataFrameから、以下の2つを生成するPythonスクリプトを作ってください。
1. サプライヤー別の発注書CSV
- サプライヤーIDでグループ化
- 発注日、品目コード、品目名、発注量、単位を含む
- ファイル名は「発注書_YYYYMMDD_サプライヤーID.csv」
2. Slack webhook通知
- 発注品目数・発注量の合計をサマリーとして送信
- 要早期発注フラグ(lead_time>=2日)がある品目は冒頭でハイライト
- Slack webhook URLは環境変数 SLACK_WEBHOOK_URL から読む
Slack webhook URLをコードにハードコードしないこと。
発注書生成・通知スクリプト
import pandas as pd
import os
import json
import urllib.request
from datetime import datetime
from pathlib import Path
SLACK_WEBHOOK_URL = os.environ.get("SLACK_WEBHOOK_URL") # 環境変数から取得
ORDER_OUTPUT_DIR = Path("./orders")
ORDER_OUTPUT_DIR.mkdir(exist_ok=True)
def generate_order_sheets(order_df: pd.DataFrame, item_master: pd.DataFrame) -> list[str]:
"""
サプライヤー別の発注書CSVを生成する
Returns:
生成したファイルパスのリスト
"""
today_str = datetime.today().strftime("%Y%m%d")
# 品目名をマスターからマージ
df = order_df.merge(item_master[["item_code", "item_name"]], on="item_code", how="left")
df = df[df["order_qty"] > 0] # 発注量0の品目を除外
generated_files = []
for supplier_id, group in df.groupby("supplier_id"):
output_cols = ["item_code", "item_name", "order_qty", "order_unit"]
sheet = group[output_cols].copy()
sheet.insert(0, "order_date", today_str)
sheet.insert(1, "supplier_id", supplier_id)
filename = ORDER_OUTPUT_DIR / f"発注書_{today_str}_{supplier_id}.csv"
sheet.to_csv(filename, index=False, encoding="utf-8-sig") # BOM付きUTF-8
generated_files.append(str(filename))
print(f"発注書生成: {filename} ({len(sheet)}品目)")
return generated_files
def send_slack_notification(order_df: pd.DataFrame, generated_files: list[str]) -> bool:
"""
Slack webhookに発注サマリーを送信する
Returns:
送信成功の場合 True
"""
if not SLACK_WEBHOOK_URL:
print("WARNING: SLACK_WEBHOOK_URL が設定されていません。Slack通知をスキップします。")
return False
df = order_df[order_df["order_qty"] > 0]
# 要早期発注フラグのある品目をハイライト
early_orders = df[df["needs_early_order"] == True]
early_block = ""
if len(early_orders) > 0:
early_items = ", ".join(early_orders["item_code"].tolist())
early_block = f":warning: *要早期発注 ({len(early_orders)}品目)*: {early_items}\n"
message = {
"text": (
f":fork_and_knife: *食材発注サマリー {datetime.today().strftime('%Y-%m-%d')}*\n"
f"{early_block}"
f"発注品目数: {len(df)} 品目\n"
f"発注書生成: {len(generated_files)} ファイル\n"
f"---\n"
f"このメッセージはAIによる自動集計です。"
f"*発注実行前に担当者が内容を確認してください。*"
)
}
try:
data = json.dumps(message).encode("utf-8")
req = urllib.request.Request(
SLACK_WEBHOOK_URL,
data=data,
headers={"Content-Type": "application/json"}
)
with urllib.request.urlopen(req, timeout=10) as res:
if res.status == 200:
print("Slack通知 送信成功")
return True
except Exception as e:
print(f"Slack通知 送信失敗: {e}")
return False
LINE Messaging APIを使う場合も、環境変数からチャンネルアクセストークンとユーザーIDを読み込む形にすることで、コードにシークレットを埋め込まないようにできます。
FC展開時の承認フローについては、本部側でSlackのワークフロービルダーを使って「承認ボタン付きメッセージ」を設定することで、加盟店SVが承認してから発注書が送信される仕組みにできます。
Step 5:実績フィードバックによる精度改善
自動化で一番見落とされがちなのが「改善ループ」です。初日から完璧な精度は出ません。廃棄・欠品・実際の発注量を記録してモデルに戻す仕組みを最初から設計しておくことが重要です。
Claude Codeへの指示文(プロンプト例5)
予測精度を改善するために、実績データをフィードバックするスクリプトを作ってください。
【記録する実績データ】
- 廃棄記録: 品目コード・日付・廃棄量・廃棄理由
- 欠品記録: 品目コード・日付・欠品時刻・欠品量(推定)
- 実発注量: 予測量に対して担当者が最終的に発注した量
【出力】
- 品目別の予測誤差トレンドCSV(週次集計)
- 廃棄率が高い品目のランキング(上位10品目)
- 欠品率が高い品目のランキング(上位10品目)
このデータが蓄積されることで、安全在庫係数の調整根拠になるようにしてください。
フィードバック集計スクリプト
import pandas as pd
from datetime import datetime, timedelta
def aggregate_feedback(
waste_log: pd.DataFrame, # 廃棄記録
shortage_log: pd.DataFrame, # 欠品記録
order_actual: pd.DataFrame, # 実発注量
predictions: pd.DataFrame, # 予測量(照合用)
weeks: int = 4,
) -> dict:
"""
過去N週の実績フィードバックを集計する
Returns:
{
"waste_ranking": DataFrame, 廃棄量上位10品目
"shortage_ranking": DataFrame, 欠品率上位10品目
"accuracy_trend": DataFrame, 品目別予測誤差週次トレンド
"coef_adjustments": DataFrame, 安全在庫係数の推奨調整値
}
"""
cutoff_date = (datetime.today() - timedelta(weeks=weeks * 7)).strftime("%Y-%m-%d")
# 廃棄ランキング(直近N週)
waste_recent = waste_log[waste_log["date"] >= cutoff_date]
waste_ranking = (
waste_recent.groupby("item_code")["waste_qty"]
.sum()
.sort_values(ascending=False)
.head(10)
.reset_index()
)
# 欠品ランキング
shortage_recent = shortage_log[shortage_log["date"] >= cutoff_date]
shortage_ranking = (
shortage_recent.groupby("item_code")["shortage_qty"]
.sum()
.sort_values(ascending=False)
.head(10)
.reset_index()
)
# 予測誤差(MAPE)週次トレンド
merged = order_actual.merge(
predictions[["item_code", "target_date", "pred_lr", "pred_baseline_ma7", "model_recommended"]],
left_on=["item_code", "date"],
right_on=["item_code", "target_date"],
how="inner"
)
merged["pred_used"] = merged.apply(
lambda r: r["pred_lr"] if r["model_recommended"] == "lr" else r["pred_baseline_ma7"],
axis=1
)
merged["date"] = pd.to_datetime(merged["date"])
merged["week"] = merged["date"].dt.isocalendar().week
accuracy_trend = (
merged.groupby(["item_code", "week"])
.apply(lambda g: pd.Series({
"mape": abs(g["actual_qty"] - g["pred_used"]).sum() / (g["actual_qty"].sum() + 1)
}))
.reset_index()
)
# 安全在庫係数の推奨調整
# ※ 廃棄多い → 係数を下げる / 欠品多い → 係数を上げる(仮定値)
coef_adj = pd.DataFrame({
"item_code": list(
set(waste_ranking["item_code"].tolist() + shortage_ranking["item_code"].tolist())
)
})
coef_adj["adjustment"] = coef_adj["item_code"].apply(
lambda x: -0.05 if x in waste_ranking["item_code"].values
else (0.05 if x in shortage_ranking["item_code"].values else 0)
)
# ※ ±0.05 の調整幅は試算値です。実際の運用では段階的に調整してください
return {
"waste_ranking": waste_ranking,
"shortage_ranking": shortage_ranking,
"accuracy_trend": accuracy_trend,
"coef_adjustments": coef_adj,
}
FC本部から加盟店への展開設計
1店舗での実装が完成したら、FC展開時に必要な設計ポイントを整理します。
多店舗対応の設計原則
| 項目 | 1店舗運用 | FC展開(多店舗) |
|---|---|---|
| POSデータ取得 | 手動CSV出力 | APIまたはSFTP自動連携 |
| 予測モデル | 全店舗共通モデル | 店舗×エリア別モデル(近隣特性を反映) |
| 発注承認フロー | 担当者が直接確認 | 本部承認 → 加盟店確認 → 実行の2段階 |
| サプライヤー連携 | CSV/PDF送付 | EDI連携または発注APIを検討 |
| アレルゲンマスター | ローカル管理 | 本部一元管理・加盟店は参照のみ |
承認フローの実装パターン(Slack)
# Slackのインタラクティブコンポーネントを使った承認フロー
# ※ この実装にはSlack Appの設定(Interactive Components有効化)が必要です
approval_message = {
"text": "食材発注の承認依頼",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*本日の食材発注案*\n発注品目: {item_count}品目\n---\n担当者の確認をお願いします。"
}
},
{
"type": "actions",
"elements": [
{
"type": "button",
"text": {"type": "plain_text", "text": "承認して発注"},
"style": "primary",
"value": "approve_order",
"action_id": "approve_food_order"
},
{
"type": "button",
"text": {"type": "plain_text", "text": "修正する"},
"value": "modify_order",
"action_id": "modify_food_order"
}
]
}
]
}
メニュー開発とデータ連携については 飲食チェーンのメニュー開発をClaude Codeで効率化する実装ガイドも参照してください。メニュー改廃のタイミングで食材マスターを更新する運用フローと組み合わせると、食材データの一元管理がより堅固になります。
発注と同じく毎日発生する記録業務は「HACCP記録をClaude Codeで支える方法」も参考になります。
【要注意】よくある失敗パターンと回避策
失敗1:データを渡しただけで「予測してくれた気になる」
❌ 「Claude CodeにCSVを渡したら自動で予測してくれるはず」
⭕ Claude Codeはコードを生成するツールです。「どんな特徴量を使うか」「モデルの評価基準は何か」「外れ値をどう扱うか」は人が設計して指示する必要があります。プロンプトで「仮定がある場合は明記して」と必ず伝えましょう。
失敗2:アレルゲンマスターをPOSデータと同じテーブルに混ぜる
❌ POSの売上テーブルにアレルゲンフラグを列として追加する
⭕ 食品表示法(消費者庁、2015年施行)の対象となるアレルゲン情報は、更新頻度・管理責任者・参照権限が異なります。別テーブル(アレルゲンマスター)として管理し、食品表示士・栄養士が管理責任を持つ体制にしてください。混ぜると、POSデータの更新でアレルゲン情報が上書きされるリスクがあります。
失敗3:予測結果を人の確認なしに直接サプライヤーに送る
❌ 「全自動化を目指して、予測→発注をワンクリックで」
⭕ 予測モデルは外れることがあります。特に初期導入後の数週間は、担当者が予測値と実績を比較しながらモデルを検証する期間が必要です。承認ステップを設けずに本番運用すると、発注ミスが発生した際の責任所在も曖昧になります。Claude Codeで作った仕組みはあくまでも「意思決定の補助ツール」として位置づけ、最終発注判断は人が行う設計にしてください。
失敗4:天気APIのクォータを考慮しない
❌ 毎日100店舗分のデータをリアルタイムで天気APIから取得する設計
⭕ OpenMeteo APIは無料プランで日次リクエストに上限があります(2026年5月時点:1日1万リクエスト・非商用、OpenMeteo公式ドキュメント参照)。100店舗×3日分の天気データを取得する場合は、前日夜にバッチで取得してローカルにキャッシュする設計にしてください。
実装ロードマップ:3フェーズで段階展開
| フェーズ | 期間(目安) | 実装内容 | KPI |
|---|---|---|---|
| Phase 1:単店舗POC | 1〜2ヶ月 | Step 1〜3(CSVからの発注量算出)を1店舗で試験運用。担当者が毎日手動で確認しながら精度を検証 | 予測誤差(MAPE)30%未満、担当者の確認時間が従来比で短縮されているか |
| Phase 2:通知・承認フロー整備 | 2〜3ヶ月 | Step 4(Slack通知・承認フロー)を追加。フィードバックループ(Step 5)の記録開始。アレルゲンマスター整備 | 承認リードタイムの短縮、廃棄記録の蓄積件数、欠品発生件数のモニタリング |
| Phase 3:多店舗展開 | 4〜6ヶ月 | 複数店舗へのロールアウト。POSデータの自動連携(API/SFTP)。本部承認フロー。店舗別モデルへの分岐 | 展開店舗数、全店舗での予測誤差中央値、担当者の工数削減量(試算ベース) |
重要: このロードマップは想定シナリオを基にした参考値です。実際の期間・KPIは店舗規模・POSシステムの種類・担当者のリソースによって大きく変わります。組織の規程・コンプライアンスに従って計画してください。
食品表示法・アレルゲン対応の基礎知識
食材発注の自動化を進める上で、食品表示法への対応は避けて通れません。ここでは基本的な要点を整理します。
特定原材料8品目(必ずアレルゲンマスターに含める)
食品表示法では、特定原材料として以下8品目の表示が義務づけられています(消費者庁「食品表示基準」に基づく、2026年5月時点):
- えび・かに・くるみ・小麦・そば・卵・乳・落花生
さらに、特定原材料に準ずるもの(推奨表示)として20品目が定められています。食材マスターを設計する際は、これらのフラグを品目ごとに管理する列を設けてください。
# アレルゲンフラグの例(必須8品目)
ALLERGEN_BIG8 = [
"shrimp", # えび
"crab", # かに
"walnut", # くるみ
"wheat", # 小麦
"buckwheat", # そば
"egg", # 卵
"milk", # 乳
"peanut", # 落花生
]
# 食材マスターに含めるカラム例
item_master_schema = {
"item_code": str,
"item_name": str,
"allergen_flags": list, # ALLERGEN_BIG8のうち該当するものをリストで
"is_frozen": bool, # 冷凍品フラグ(解凍後の再凍結制限に関係)
"storage_temp_max": float,# 保管温度上限(℃)
"best_before_days": int, # 賞味期限(日)
"updated_at": str, # 最終更新日(変更追跡用)
}
# ※ アレルゲン情報の設定・更新は必ず食品表示士・栄養士等の専門家が確認してください
最新の食品表示基準については、必ず消費者庁の公式ページ(caa.go.jp)で確認してください。基準は改正されることがあります。
まとめ:今日から始める3つのアクション
飲食チェーンの食材発注自動化をClaude Codeで実装するポイントをまとめます。
- 今日やること:Step 1のPOS CSV整形プロンプトをClaude Codeに渡し、手元のCSV1ファイルで動作確認する。エンコーディングエラーが出たらShift-JIS/CP932を試す。
- 今週中:Step 2の需要予測スクリプトを1品目に絞って実行し、移動平均と線形回帰のMAPEを比較する。MAPE 25%未満が達成できるかどうかがStep 3以降の展開判断基準になります。
- 今月中:Phase 1 POCとして担当者と1店舗試験運用の計画を立てる。承認フローとアレルゲンマスターの設計を先行して決めておく。
正直なところ、「食材発注の完全自動化」はゴールとして設定しない方が長続きします。Claude Codeで作った仕組みを「現場の判断を補助するダッシュボード」として位置づけ、担当者が最終的な発注量を修正できる余地を残す設計にすることで、現場の納得感と精度改善が両立します。
シフト計画と組み合わせた飲食チェーン全体の自動化については 飲食チェーンのシフト計画をClaude Codeで自動化する実装ガイドをあわせてご参照ください。
参考・出典
- 消費者庁「食品表示法に基づく食品表示基準」(参照日:2026年5月)
- OpenMeteo API公式ドキュメント(参照日:2026年5月)
- Anthropic「Claude Code Overview」(参照日:2026年5月)
よくある質問
Q1. POSシステムの種類によって実装は変わりますか?
A. CSVのエクスポート形式・列名・文字コードは機種によって異なりますが、Step 1のデータ整形スクリプトを調整することで対応できます。APIでデータ連携できるPOSシステムの場合は、CSV不要でリアルタイム取得も可能です。POSベンダーのAPIドキュメントを確認し、所属組織のシステム担当者に相談してください。
Q2. 天気データは必須ですか?有料ですか?
A. 天気データは精度向上に有効ですが、必須ではありません。まず曜日・連休フラグだけで移動平均と線形回帰を試し、誤差が改善しない場合に追加する段階的なアプローチを推奨します。OpenMeteo APIは非商用・一定量までは無料で利用できます(2026年5月時点、公式ドキュメントで最新の利用規約を確認してください)。
Q3. アレルゲン情報の管理はClaude Codeに任せられますか?
A. Claude Codeはアレルゲンマスターの管理スクリプトの生成や、データ設計の補助はできます。ただし、アレルゲン情報の設定・更新の確認は必ず食品表示士・栄養士等の専門家が行ってください。食品表示法への対応は法令リスクを伴うため、AIツールのみで判断しないことを強く推奨します。
Q4. FC加盟店への展開時、本部と加盟店でコードを共有する方法は?
A. GitHubのプライベートリポジトリで管理し、本部が設定する品目マスター・サプライヤー情報は環境変数または設定ファイルで分離するのが一般的です。加盟店ごとにブランチを切る方法と、マルチテナント設計(店舗IDで分岐)の2パターンがあります。規模・技術リソースに応じて選択してください。
Q5. 実装に必要なプログラミングの知識レベルは?
A. PythonのPandas基礎(DataFrameの読み込み・集計・結合)と、コマンドラインの基本操作ができれば進められます。Claude Codeへの指示文(プロンプト)の書き方が実装品質を左右するため、「仮定を明記して」「エラーハンドリングを含めて」等の条件を付けて指示することが重要です。


