
「深夜2時、アラートで叩き起こされてダッシュボードを5枚開いて、ログをgrepしながら頭の中で仮説を立てる」——SRE・インフラ運用をやっていると、これが日常茶飯事ですよね。正直、この「調査して仮説を立てて手順書に落とす」という反復作業の多くは、AIに下書きを作らせて自分が判断する形に分担できます。本記事では、Claude Codeを使ってログ調査・監視設定・IaC・ランブック・運用自動化をどう効率化するか、実際のプロンプトとコード例つきで整理しました。
結論:Claude Codeは「調査と下書き」を担当、判断と実行は人間が握る
結論を1文で言うと、SRE運用におけるClaude Codeの正しい使い方は「本番の実行役」ではなく「ログ調査・仮説出し・設定/手順の下書き役」です。 AIに本番の認証情報やオペレーションの最終判断を渡さず、生成物を必ずレビューして検証環境で確かめてから本番に持っていく——この境界線さえ守れば、運用の生産性は大きく変わります。
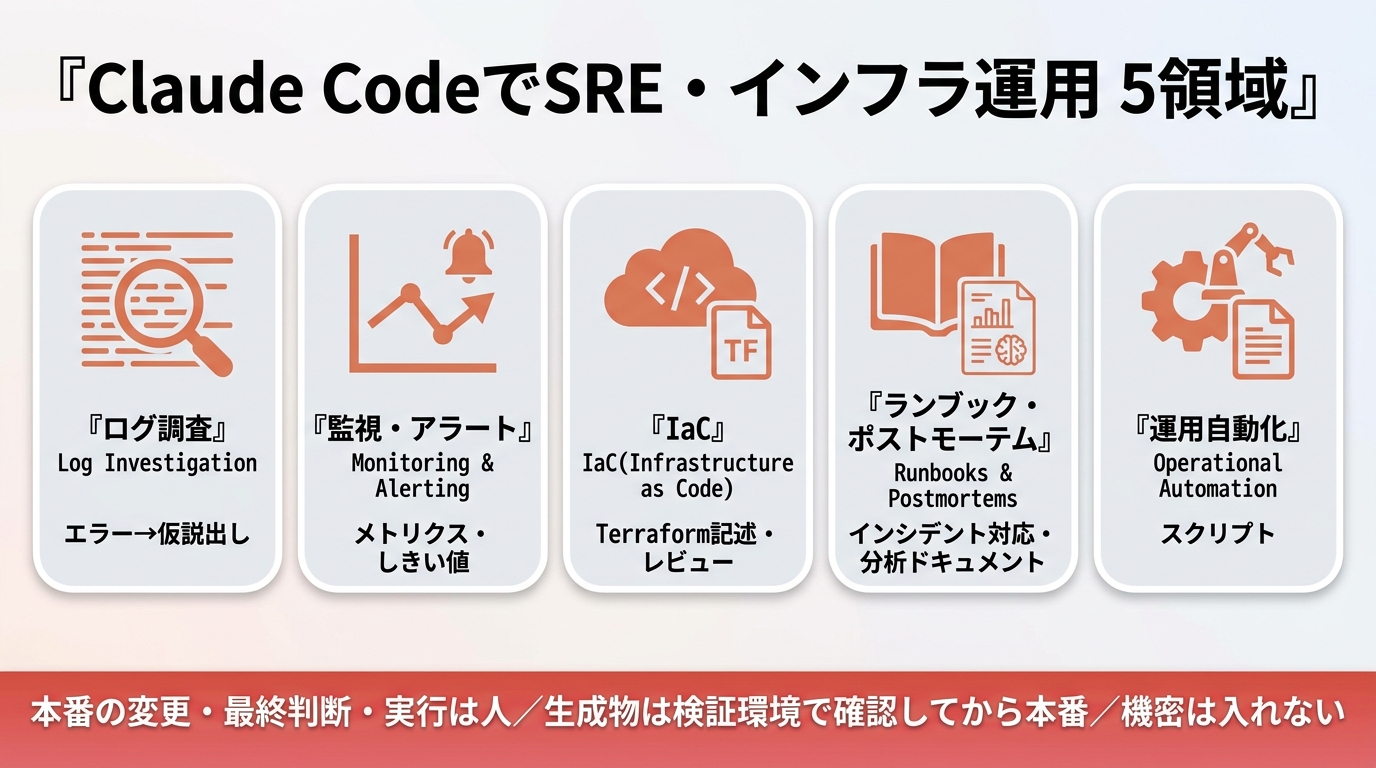
- 要点1:効率化できるのは①ログ調査・障害切り分けの補助 ②監視・アラート設定の下書き ③IaCの記述・レビュー補助 ④ランブック・ポストモーテム作成 ⑤運用スクリプト・自動化の実装、の5領域。
- 要点2:本番変更・障害対応の最終判断・破壊的操作(削除・再起動)は必ず人間が実行する。Claude Codeは権限設定やサンドボックスで「読み取り中心」に絞れる。
- 要点3:生成したコマンド・IaC・スクリプトはレビュー必須、検証環境で確認してから本番へ。AIに本番のシークレットや顧客データを入れない。
対象読者:SRE・インフラエンジニア・プラットフォームエンジニア・運用担当で、Claude Codeを日々の運用に組み込みたい人。今日やること:まずは「過去のインシデントのログ調査」をClaude Codeに手伝わせて、仮説出しと事後ポストモーテムの下書きを作るところから始めましょう。(情報は2026年6月時点)
大前提:本番に触らせない安全設計を最初に固める
ワークフローの話に入る前に、ここだけは絶対に外せません。運用の現場でAIを使うときの事故は、たいてい「やってはいけない領域」を最初に切っていなかったことが原因です。
Claude Codeはデフォルトでファイル編集やコマンド実行のたびに許可を求めますが、運用で使うときは明示的に「読み取り中心」のプロファイルに寄せるのが安全です。Claude Codeにはツールごとの許可(allow/deny)を設定ファイルで制御する仕組みがあり、プロジェクトの .claude/settings.json やユーザー設定でコントロールできます(公式docsのSettings・IAM/permissionsを参照)。
運用ディレクトリで使うときの最低限の指針をまとめます。
- 本番のシークレットを渡さない:本番の認証情報・APIキー・顧客データ・機密設定をプロンプトやコンテキストに入れない。調査に使うログは事前にマスキングする。
- 破壊的コマンドはdeny:
kubectl delete/terraform apply/systemctl restart/rm -rfなどの破壊的・本番影響系コマンドは、許可リストで明示的に拒否し、人間が手で実行する。 - 生成物は必ずレビュー+検証環境:AIが書いたコマンド・IaC・スクリプトは、そのまま本番に流さない。レビューし、ステージング等の検証環境で動作確認してから本番へ。
- サンドボックス・読み取り専用環境を使う:調査だけなら本番に書き込み権限のない環境(読み取り専用クレデンシャル、隔離されたコンテキスト)で動かす。Claude Codeのサンドボックス機能は公式のSecurityドキュメントで現行仕様を確認すること。
設定例として、運用調査用のディレクトリに置く CLAUDE.md に運用ルールを明記しておくと、毎回の指示が安定します(Memory/CLAUDE.md参照)。
# 運用ルール(このディレクトリ)
## 絶対に守ること
- 本番への変更・実行は提案しない。下書き・仮説のみ出す
- terraform apply / kubectl delete / systemctl restart / rm -rf は出力に含めない
- 本番のシークレット・顧客データはここに貼られない前提で動く
- 破壊的操作が必要なときは「人間が実行すべき手順」として手順書形式で出す
## やってよいこと
- ログの読解・パターン抽出・仮説出し
- 監視設定・IaC・スクリプトの「下書き」生成(要レビュー注記つき)
- ポストモーテム・ランブックの文章化
この「役割を最初に固める」一手間で、以降のすべての作業が安全側に倒れます。ここを飛ばすと、便利なはずのAIが事故の起点になります。
① ログ調査・障害の原因切り分けを補助する
障害対応で一番時間を食うのが、大量のログから「何が起きたか」の仮説を立てるフェーズです。ここはClaude Codeが得意で、しかも読み取りしかしないので安全に使えます。
典型的なのは、エラーログの塊を渡して「時系列で何が起きたか」「考えられる原因の候補」「次に確認すべきログ・メトリクス」を出させる使い方です。重要なのはマスキング済みのログを渡すことと、AIの仮説を鵜呑みにせず確認手順まで出させることです。
# まずログを取得し、機密情報をマスキングしてからファイルに保存
kubectl logs deploy/payment-api --since=1h \
| sed -E 's/[0-9]{1,3}(\.[0-9]{1,3}){3}/x.x.x.x/g' \
| sed -E 's/(token|authorization)=[^ ]+/\1=REDACTED/gi' \
> /tmp/incident_masked.log
# Claude Code を起動してログファイルを渡す
claude
そのうえで、こういう指示を出します。
/tmp/incident_masked.log を読んで、次を整理して。
本番への操作は提案しないこと。
1. タイムライン:何時何分に何が起きたかを時系列で
2. 観測された症状(HTTPステータス、エラー種別、頻度)
3. 考えられる原因の仮説を3つ、確からしさの根拠つきで
4. 各仮説を確認するために「人間が次に見るべき」ログ・メトリクス・コマンド
(実行はしない。確認手順の提示のみ)
不確かな点は「不明」と明示して。推測で断定しないこと。
このとき効くのが、Claude Codeの「エージェント的にファイルやコマンド結果を読みに行く」性質です。たとえば「直前のデプロイ差分も見たい」と思ったら、読み取り権限の範囲で git log や設定ファイルを参照させ、ログの異常とコード変更を突き合わせた仮説を出させられます。
❌ よくある失敗:AIの「原因はこれです」を確定として扱う。Claude Codeは限られたログから尤もらしい仮説を出しますが、根本原因の断定はしてはいけません。⭕ 正しくは「仮説リスト+確認手順」として受け取り、確認は人間がやる。AIには「断定せず、不明は不明と書け」と明示するのが効きます。
② 監視・アラート設定の下書きを作る
「このサービスにアラートを足したいけど、しきい値どうしよう」「PromQLの式を書くのが面倒」——監視設定はテキストの塊なので、下書き生成と相性が良い領域です。
たとえばPrometheus + Alertmanagerの構成で、新サービスのSLOベースのアラートを下書きさせるなら、こう指示します。出力されるPromQLや式は必ず公式仕様で裏取りし、検証環境のメトリクスで動作確認してから本番ルールに入れます(PromQL公式・Alertmanager設定)。
payment-api 向けのPrometheusアラートルールを下書きして。
前提:
- メトリクスは http_requests_total{job="payment-api"} と
http_request_duration_seconds_bucket がある
- SLO: 可用性99.9% / p99レイテンシ 500ms
作ってほしいもの:
- エラー率(5xx割合)が一定を超えたときのアラート
- p99レイテンシが閾値超過のアラート
- それぞれ severity ラベルと for(継続時間)つき
注意:
- 閾値は「初期値の提案」とし、根拠コメントを式に添えて
- これは下書き。本番投入前に検証環境で発火テストする前提で書いて
生成される rules.yml はこんな形になります(あくまで下書きの一例で、しきい値・式は自分の環境に合わせて調整・検証が必要です)。
groups:
- name: payment-api-slo
rules:
# エラー率:直近5分の5xx割合が1%超で警告(SLO 99.9%の余裕を考慮した初期値)
- alert: PaymentApiHighErrorRate
expr: |
sum(rate(http_requests_total{job="payment-api",code=~"5.."}[5m]))
/ sum(rate(http_requests_total{job="payment-api"}[5m])) > 0.01
for: 5m
labels:
severity: warning
annotations:
summary: "payment-api のエラー率が1%を超過"
description: "直近5分の5xx割合が1%超。デプロイ・依存先障害を確認。"
ダッシュボードのJSON(Grafana等)も同様に下書きできますが、こちらはパネルのクエリが正しいかを実データで必ず確認してください。AIはそれらしいJSONを出しますが、メトリクス名の存在チェックまではしてくれません。
❌ 失敗:生成されたしきい値をそのまま本番に入れてアラート嵐。AIが出す閾値は一般論なので、自社のトラフィック特性に合わずノイズになりがちです。⭕ 正しくは「初期値の提案」として受け取り、過去メトリクスでバックテスト(この閾値だと過去に何回発火したか)してから採用します。
③ IaC(Terraform等)の記述・レビューを補助する
Terraform・Kubernetesマニフェスト・Ansibleといった「設定をコードで書く」領域は、Claude Codeの本来の得意分野(コード生成・レビュー)がそのまま活きます。ただし適用(apply)は絶対に人間が、検証環境を経由して行います。
使い方は大きく2つ。記述補助(新しいリソースのHCLを書かせる)とレビュー補助(既存の差分やコードを点検させる)です。レビュー補助のほうが事故が起きにくく、価値も出やすいです。
# プランの差分を取って、それをClaude Codeにレビューさせる
terraform plan -no-color > /tmp/tf_plan.txt
claude
/tmp/tf_plan.txt は terraform plan の出力。レビューして。
apply はしないこと(提案もしない)。
観点:
1. 破壊的変更(destroy / replace)になっているリソースを最優先で列挙
2. セキュリティグループ・IAM・公開設定で危険な変更がないか
3. ステートフルなリソース(DB・ボリューム)の置き換えリスク
4. 命名・タグ・ドリフトの観点で気になる点
各指摘は「どのリソースの・どの行が・なぜ危険か」で書いて。
terraform plan の差分レビューは、destroy や replace の見落としを減らせるので相性抜群です。terraform plan / terraform validate の出力フォーマットはHashiCorp公式で確認できます。
なお、IaC変更レビューだけを深掘りした記事は別にあります。差分レビューをチームの標準フローに落とし込みたい人は Terraform変更レビューをClaude Codeで標準化|5手順 を合わせて読むと、本記事の「運用全体の中の一工程」としての位置づけがクリアになります。
記述補助を使う場合も、生成HCLは terraform validate → plan → レビュー → 検証環境で apply の順で必ず確認します。AIが書いたコードを plan なしで本番 apply するのは、運用事故の典型パターンです。
④ ランブック・手順書・ポストモーテムを作成する
SREの仕事のうち、地味だけど効くのが「ドキュメント化」です。インシデントの後に疲れた頭でポストモーテムを書くのは苦行ですが、ここはAIに下書きさせると一気に楽になります。文章化はAIの最も安全で確実な活用領域です。
ポストモーテムを書くなら、タイムラインと事実を渡して、非難なしのフォーマットで下書きさせます(Googleのポストモーテム文化のテンプレ思想に沿わせると質が安定します)。
以下の障害について、非難なし(blameless)のポストモーテム下書きを作って。
事実:
- 6/3 02:14 payment-api の5xxが急増、約18分継続
- 原因:直前デプロイで接続プールの上限設定を誤った
- 02:32 ロールバックで復旧
- 影響:決済の一部失敗(件数は別途確認中)
セクション:概要 / 影響 / タイムライン / 根本原因 /
検知できた点・できなかった点 / 再発防止アクション(担当と期限の欄つき)
注意:個人を責める表現は使わない。仕組みの問題として書く。
未確定の数値は「確認中」と明記。
ランブック(対応手順書)も同じ要領で作れます。「このアラートが鳴ったらどう動くか」を、過去のインシデント対応の流れを渡して手順化させると、属人化していた知識が文書になります。ここでも破壊的操作のステップには「人間が判断・実行」と明記させ、ワンクリックで実行する自動化に流し込まないのがポイントです。
監視の設計思想そのものを整理したいときは、Googleの分散システムの監視の章をClaude Codeに要約させ、自社の監視項目と突き合わせる、という使い方もできます。
⑤ 運用スクリプト・自動化を実装する
最後は、繰り返す運用タスクのスクリプト化です。ログ集計、定期レポート、ヘルスチェック、棚卸し——こういう「読み取り中心で、自分が中身を理解できる」自動化はClaude Codeで素早く形にできます。
ポイントは最初は読み取り専用(dry-run)から作ること。いきなり「リソースを削除するクリーンアップスクリプト」を書かせるのではなく、まず「削除候補をリストアップするだけ」のスクリプトを作り、人間が確認してから実行系を足します。
古いEBSスナップショットを棚卸しするスクリプトを書いて。
まず「削除しない・一覧表示だけ」のdry-run版にして。
要件:
- 作成から90日以上経過したスナップショットを抽出
- ID・作成日・サイズ・タグを表で出力
- 削除は行わない(--dry-run固定でいい)
- AWS CLIの read 系コマンドのみ使用
実際の削除は人間がレビュー後に手で行う前提で。
こうしたスクリプトを -p(ヘッドレス)モードで定期実行に組み込めば、棚卸しレポートを毎週Slackに流す、といった運用も作れます。ヘッドレス実行の仕様は公式のHeadlessドキュメントやSDKを参照してください。ただし自動実行に破壊的操作を組み込まない——あくまで「集める・知らせる」までを自動化し、「変える・消す」は人間のレビューを挟むのが鉄則です。
よく使う調査・レポート手順は、Claude Codeのカスタムスラッシュコマンドにしておくと、チームで再利用できます。「/incident-triage でログ調査の定型プロンプトが走る」ようにしておくと、調査の質が人によってブレなくなります。
運用に組み込むときの失敗パターンと対策
ここまでの5領域を実際にチームへ展開するときに、つまずきやすい点を整理します。
- ❌ 本番クレデンシャルが見える環境でAIを動かす → ⭕ 読み取り専用クレデンシャル・隔離環境で動かし、シークレットはコンテキストに入れない。調査ログは事前マスキングを習慣化する。
- ❌ AIの仮説や生成設定を「確定」として本番に流す → ⭕ すべて「下書き・仮説」扱い。レビュー+検証環境での確認をフローに固定する。
- ❌ 破壊的操作まで自動化に巻き込む → ⭕ 「集める・知らせる・下書きする」までを自動化し、「変える・消す・再起動する」は人間が実行。許可リストで破壊的コマンドをdenyしておく。
- ❌ 権限設定をデフォルトのまま使う → ⭕ 運用ディレクトリでは設定で読み取り中心プロファイルに寄せる。Claude Codeサンドボックスで安全に自動実行の考え方を運用にも適用する。
Claude Code全体の使い方を体系的に押さえたい人は、Claude Code 実践テクニック完全ガイドから入ると、本記事のSRE特化ワークフローがどの土台の上に乗っているかが見えてきます。
まとめ:境界線を引けば、運用は確実に楽になる
SRE・インフラ運用におけるClaude Code活用の本質は、「AIに何をさせないか」を先に決めることです。本番の実行と最終判断は人間が握る。AIにはログ調査・監視/IaC/スクリプトの下書き・ランブックやポストモーテムの文章化を任せる。この境界線さえ守れば、深夜のインシデント対応も、地味なドキュメント仕事も、確実に軽くなります。
まずは小さく、過去のインシデント1件のログ調査とポストモーテム下書きから試してみてください。読み取りしかしない安全な使い方なので、今日から始められます。(本記事の情報は2026年6月時点。Claude Codeの権限設定・サンドボックス等の機能仕様は更新されるため、本番適用前に必ず公式ドキュメントで最新仕様を確認してください)
次のアクション
- 今日:過去インシデント1件のマスキング済みログをClaude Codeに渡し、タイムライン+仮説+確認手順を出させる。
- 今週:運用ディレクトリに
CLAUDE.mdと読み取り中心の許可設定を置き、破壊的コマンドをdenyする。 - 今月:ログ調査・ポストモーテムの定型プロンプトをカスタムスラッシュコマンド化し、チームで共有する。
著者プロフィール
佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援に携わる。著書『AIエージェント仕事術』(SBクリエイティブ)。SoftBank IT連載7回執筆。


