結論:パフォーマンスチューニングは「速くしたい場所を直感で直す」のではなく、計測してボトルネックを特定し、改善し、再計測して数値で効果を確認するループです。Claude Code はこのループの「プロファイル結果の解釈」と「改善案の実装」を加速させる相棒として使うのが正解で、改善案の採否は必ず実測で判断します。
- 要点1:まず計測する。「ここが遅そう」という推測ではなく、プロファイラやベンチマークで遅い箇所を数値で押さえる(”推測するな、計測せよ” — Rob Pike の Programming Rule から広く引用される原則)。
- 要点2:プロファイル結果(`cProfile` / `perf_hooks` の出力)を Claude Code に読ませてボトルネックを解釈させ、アルゴリズム・クエリ・キャッシュの3方向から改善案を出させる。
- 要点3:1つ変えたら必ず同じベンチマークで再計測し、効果(例: 880ms → 120ms)を数値で確認する。効果が出なければ戻す。これを回帰テストに固定して劣化を防ぐ。
対象読者:Web/バックエンドの開発者、PM、レイテンシ改善を任されたエンジニア。Python / Node.js のサンプルで進めますが、考え方は言語に依存しません。
今日やること:遅いと感じている処理を1つ選び、プロファイラを1回かけて「最も時間を食っている関数」をメモする。改善はその後です。
「このAPI、なんか遅いんだよね」——開発を進めていると、必ずこの局面に出くわします。やっかいなのは、遅い原因が体感とほぼ一致しないことです。大手SaaSの開発チームを個別サポートしたときも、「ここが重いはず」と全員が指していたループは実は数msで、実際のボトルネックは見落とされていた N+1 クエリでした。直感で手を入れていたら、何時間かけても速くならなかったはずです。
本記事は、Claude Code を使ってパフォーマンスチューニングを「計測ファースト」で進める実践ガイドです。①計測 → ②ボトルネック特定 → ③改善案の検討 → ④実装と再計測 → ⑤回帰防止、の5手順を、コピペできるプロンプトとコード例つきで解説します。本記事の数値(880ms→120ms 等)はすべて説明用のサンプル値(想定シナリオ)であり、あなたの環境では必ず自分で計測してください。情報は2026年6月時点のものです。
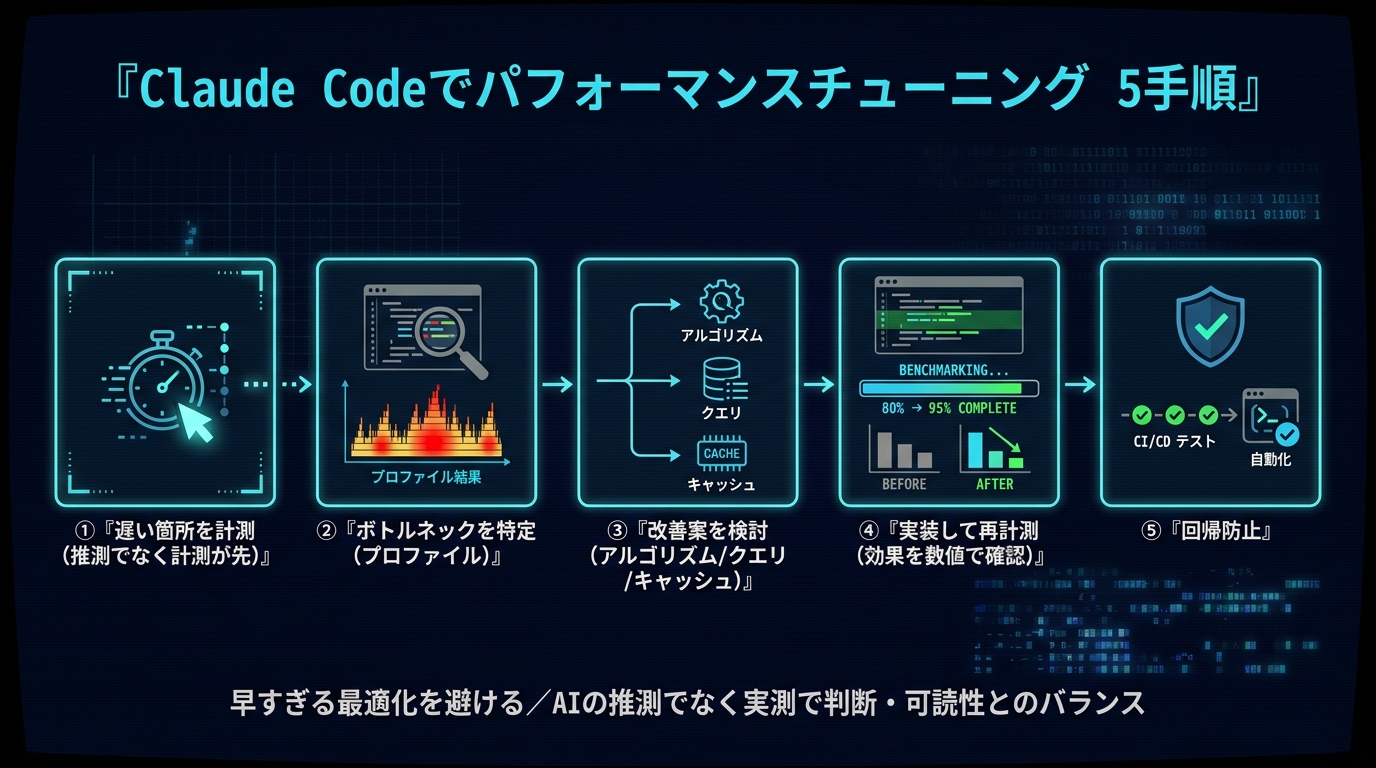
手順1:まず計測する — 推測でなく数値でボトルネックを掴む
パフォーマンスチューニングの最大の落とし穴は、計測する前にコードを直し始めることです。プログラミングの古典的な格言に「推測するな、計測せよ(Don’t guess, measure)」があります。人間の「ここが遅そう」という感覚は、実測とかなりの確率でズレます。だからチューニングの第一歩は、必ずプロファイラかベンチマークを「先に」かけることです。
Python なら標準ライブラリの cProfile がそのまま使えます。Claude Code に計測の足場を作ってもらいましょう。
遅い処理を計測したい。cProfile で計測するスクリプトを書いてほしい。
- 対象: src/report.py の generate_report() 関数
- 実行回数: ウォームアップ1回 + 計測5回の中央値
- 出力: cumulative time でソートした上位20関数を表示
- ベンチマーク用の固定入力を fixtures/ から読む形にする
不足している情報があれば、最初に質問してから作業を開始してください。
仮定した点は必ず"仮定"と明記してください。生成されるのは、たとえば次のような計測コードです。計測条件(入力・回数・環境)を固定するのが肝で、これがないと「速くなった気がする」だけで終わります。
import cProfile, pstats, io
from statistics import median
import time
from src.report import generate_report
# ウォームアップ(JIT・キャッシュ・コネクション確立の影響を除く)
generate_report(load_fixture())
# 5回計測して中央値を取る(外れ値の影響を抑える)
durations = []
for _ in range(5):
t0 = time.perf_counter()
generate_report(load_fixture())
durations.append(time.perf_counter() - t0)
print(f"median: {median(durations)*1000:.1f}ms")
# どの関数が重いかを cProfile で詳細プロファイル
pr = cProfile.Profile()
pr.enable()
generate_report(load_fixture())
pr.disable()
s = io.StringIO()
pstats.Stats(pr, stream=s).sort_stats("cumulative").print_stats(20)
print(s.getvalue())Node.js なら perf_hooks の performance.now() で区間を測るか、起動時に node --prof を付けて V8 プロファイルを取得します。いずれにせよ、まず「合計時間」と「関数別の内訳」の2つを手元に出すことがゴールです。
この段階での合言葉は「数字が出るまでコードを触らない」。計測なしの最適化は、効果が出たのか運が良かったのか区別できません。
手順2:ボトルネックを特定する — プロファイル結果をClaude Codeに読ませる
プロファイル結果は数十行〜数百行になり、初見では「どこを見ればいいか」が分かりにくいものです。ここが Claude Code の出番です。生のプロファイル出力を貼り付けて解釈させると、ボトルネックの当たりが一気につきます。
以下は cProfile の出力(cumulative ソート上位20)です。
このコードベースを読んだうえで解釈してください。
[ここにプロファイル出力を貼り付け]
知りたいこと:
1. 実際のボトルネックはどの関数か(自己時間 tottime と累積 cumtime を区別して)
2. その関数が遅い構造的な理由(ループ / I/O / 重複計算 / N+1 など)
3. 「速そうに見えて実は誤差」な箇所があれば指摘
数字と固有名詞は、根拠(出典/計算式)を添えてください。
推測の場合は必ず"仮定"と明記してください。ここで重要なのは tottime(その関数自身が使った時間)と cumtime(呼び出した先も含む累積時間)の区別です。cumtime が大きい関数は「下流が重い入口」かもしれず、本当の犯人は呼び出し先にいることがあります。Claude Code にこの区別を意識して読ませると、「入口の generate_report ではなく、その中で50回呼ばれている fetch_user() の I/O が支配的」といった具体的な指摘が返ってきます。
典型的なボトルネックは次の3カテゴリに収まることが多く、当たりをつける手がかりになります。デバッグ寄りの調査手順はClaude Codeでデバッグ・障害調査を効率化する実践ガイドも合わせて参照してください。
- アルゴリズム:O(n²) のネストループ、毎回ソートし直す、不要な全件走査
- I/O・クエリ:N+1 クエリ、インデックス未使用、ループ内の同期API呼び出し
- 重複計算・キャッシュ不在:同じ入力に対する再計算、メモ化できる純粋関数
手順3:改善案を検討する — アルゴリズム / クエリ / キャッシュの3方向
ボトルネックが分かったら、改善案を「いきなり1つに決め打ち」せず、複数案を出してトレードオフを比較します。早すぎる最適化(premature optimization)を避けるためにも、可読性とのバランスを必ず一緒に検討させるのがコツです。
具体的な改善手順は <ol> の流れで進めます。
- 改善案を3つ出させる:「アルゴリズムを変える案」「クエリ/I/Oを直す案」「キャッシュを足す案」をそれぞれメリット・デメリット・実装コストつきで列挙させる。
- 最小の変更から選ぶ:同じ効果が見込めるなら、行数が少なく可読性を壊さない案を優先する。N+1 の解消(一括取得)は多くの場合これに当たる。
- 1案だけ実装する:複数を同時に入れると、どれが効いたか分からなくなる。1変更1計測を徹底する。
改善案を出させるプロンプトの例です。
generate_report の中で fetch_user() が50回ループで呼ばれ、各回でDBに行っている(N+1)。
改善案を3方向で出してほしい。
1. アルゴリズム視点(ループ構造そのものを変える)
2. クエリ視点(一括取得 / JOIN / インデックス)
3. キャッシュ視点(メモ化 / 短期キャッシュ)
各案について「想定効果の根拠」「可読性への影響」「導入リスク」を表で比較してください。
最も変更が小さく効果が大きい案を最後に推奨として1つ挙げてください。
ただし、効果は実装後に私が計測して確認します。断定はしないでください。ここで Claude Code が「N+1 を一括取得に変えれば DB ラウンドトリップが50回→1回になり、ネットワーク往復分が支配的に減るはず(要計測)」と根拠つきで、かつ断定せずに提案してくれれば理想的です。改善案はあくまで仮説であり、採用の最終判断は次の手順4の再計測でくだします。大規模なコードでボトルネックの周辺構造を把握する手順はClaude Codeで大規模コードベースを理解する|新人即戦力化が参考になります。
手順4:実装して再計測する — 効果を数値で確認する
改善を実装したら、手順1とまったく同じ条件のベンチマークを回します。入力・回数・環境を変えてしまうと比較が成立しません。Claude Code には「Before/After を同一スクリプトで並べて出す」ところまでやってもらいましょう。
fetch_user() の N+1 を fetch_users_bulk() による一括取得に置き換えた。
手順1と同じベンチマーク(ウォームアップ1回 + 5回計測の中央値)で
Before/After を比較するスクリプトに更新してほしい。
- 同じ fixtures/ の固定入力を使う
- 出力: before_median_ms / after_median_ms / 改善率(%)
- 結果が誤差レベル(±5%以内)なら「効果なし」と明示するたとえば次のような結果が出れば、改善は成功です(数値はサンプル)。
before_median: 880.4ms
after_median: 121.7ms
改善率: -86.2% (DBラウンドトリップ 50回 → 1回)逆に、改善率が ±5% に収まっていたらその変更は捨てて元に戻します。「コードは複雑になったのに速くなっていない」のは純粋な技術的負債です。AI が出した改善案であっても、再計測で効果が確認できなければ採用しない——これがこのループの一番大事なルールです。AIの推測ではなく、自分の実測で判断するを最後まで貫いてください。
もう一段の高速化が必要なら、手順1に戻って「次に重い関数」をプロファイルし直します。1ループで1ボトルネックを潰し、効果が頭打ちになったらやめる。最適化は「十分速くなったらやめる」のが正しい止め方です。
手順5:回帰を防ぐ — ベンチマークをテストに固定する
せっかく速くしても、半年後のリファクタで元に戻っていた、というのはよくある話です。これを防ぐには、パフォーマンスをテストとして固定します。Claude Code にベンチマークを CI 用のテストへ変換させましょう。
手順4のベンチマークを pytest のテストに変換してほしい。
- generate_report() の中央値が 300ms を超えたら fail する
- 閾値は環境差を考慮して「現状値 × 2.5」を上限の目安に設定
- CI(GitHub Actions)で動くよう、計測回数は3回に減らしてもよい
- なぜこの閾値かをコメントで残す
YMYL的な保証はしない前提で、あくまで「明らかな劣化検知」用とすること。パフォーマンステストは厳しすぎると環境差で頻繁に落ちて形骸化します。「絶対値を保証する」のではなく「明らかな劣化を検知する」くらいの緩い閾値(現状の2〜3倍)にしておくのが実用的です。テスト自動化全般の組み込み方はClaude CodeでQA・テスト自動化を加速する実践ガイドに詳しくまとめています。あわせて、Claude Code 全体の使いこなしはClaude Code 実践テクニック完全ガイド|12スキル学習順のピラー記事から辿れます。
【要注意】よくある失敗パターンと回避策
パフォーマンスチューニングで踏みがちな地雷を、エンジニア視点で整理します。
❌ 失敗1:計測せずに最適化を始める
「ここが遅そう」で手を入れる。直感は高確率で外れ、時間だけ溶ける。
⭕ 回避策:必ずプロファイラを先にかける。”推測するな、計測せよ” を徹底。数字が出るまでコードに触らない。
❌ 失敗2:早すぎる最適化(premature optimization)
まだ遅くもない箇所を、将来のためにと先回りで複雑化する。可読性が下がり、バグの温床になる。
⭕ 回避策:実際に計測でボトルネックと確定した箇所だけ直す。「動く・読める」を優先し、遅くなってから最適化する。
❌ 失敗3:AIの改善案を再計測せずに採用する
Claude Code が「これで速くなります」と出した案を、効果確認せずマージする。実は誤差だった、ということが起きる。
⭕ 回避策:AIの提案は仮説として扱い、Before/After を同一条件で計測してから採否を決める。効果が出なければ戻す。
❌ 失敗4:可読性を犠牲にした過剰最適化
数msのために誰も読めないトリッキーなコードを書く。チューニング箇所が局所的な負債になる。
⭕ 回避策:効果(ms)と可読性のトレードオフを毎回天秤にかける。微小な効果なら可読性を優先する判断も「正解」。
まとめ:今日から始める3つのアクション
パフォーマンスチューニングは才能ではなく手順です。Claude Code を「計測結果の解釈役」と「改善案の壁打ち相手」に使い、判断は必ず実測でくだす——これだけで再現性が大きく上がります。
- 遅い処理を1つ選んでプロファイルする:`cProfile` か `perf_hooks` で、まず「最も時間を食っている関数」を数字で特定する。
- プロファイル出力をClaude Codeに読ませる:tottime と cumtime を区別させ、アルゴリズム/クエリ/キャッシュの3方向で改善案を出させる。
- 1変更1計測のループを回す:1つ直して再計測、効果がなければ戻す。効いた改善はパフォーマンステストに固定して回帰を防ぐ。
Uravation では、Claude Code を使ったパフォーマンス改善・コードベース理解の進め方を、開発チーム向けに個別サポートしています。「自社のこの処理、どう計測して何から直せばいいか」を一緒に手を動かして詰めたい方は、お気軽にご相談ください。
著者プロフィール
佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援を展開。著書『AIエージェント仕事術』(SBクリエイティブ)。