
結論:自治体の条例改正作業において、Claude Codeは「改正前後テキストの差分抽出」「新旧対照表の自動生成」「関連条文の整合チェック補助」という3つの定型作業を大幅に省力化できる。ただし最終判断は法制執務担当が必ず行う設計が前提となる。
- 要点1:Pythonの
difflibを使えば改正前後の例規テキストを自動比較し、変更箇所を可視化したHTMLレポートを出力できる - 要点2:Claude Codeへのプロンプト設計次第で、新旧対照表(2カラム形式)の草案生成から他条文との参照整合チェックの補助まで一連の作業を支援できる
- 要点3:機微情報を外部APIに送信しない設計(オフライン処理優先・ローカル実行)が自治体の情報セキュリティポリシーと整合する
対象読者:自治体の情報政策課・法制執務担当・GovTechエンジニア、および自治体DX支援ベンダーのエンジニア・コンサルタント
今日やること:本記事末尾のサンプルコードを手元の例規テキストに適用し、差分HTMLレポートを1件生成してみる
「新旧対照表、また手作業で作るの?」
自治体の法制執務担当者から、研修や支援の場でこの言葉を何度聞いたかわかりません。条例改正のたびに、改正前と改正後を2カラムで並べた「新旧対照表」を手作業で作成し、変更箇所を目視で確認する—この作業が、担当者の大きな負荷になっているというのは、多くの自治体で共通した課題です。
実際に支援した自治体向けプロジェクト(想定シナリオを含む)では、一つの条例改正で新旧対照表の作成に平均3〜5時間かかっていたケースがありました。しかも、改正が複数の条文にまたがる場合や、他の条例・規則との参照関係が生じる場合には、さらに時間と注意力が必要になります。
本記事では、Claude Codeを活用して「条例・例規改正の差分チェックと新旧対照表作成」を支援する実装パターンを紹介します。自治体特有の情報セキュリティ要件(LGWAN環境、総務省ガイドライン準拠)を考慮した設計と、「最終判断は人間が行う」原則を守るための協働設計について詳しく解説します。
なお、本記事で紹介する実装は想定シナリオおよびリファレンス実装パターンとして構成しています。実際の自治体への適用にあたっては、各自治体の情報セキュリティポリシーおよびシステム管理規程に従ってください。
自治体の法制執務業務とAI活用の現状
まず、自治体の条例改正業務の実態を整理しておきましょう。
自治体は、国の法律改正・政令改正に対応した条例・規則の改正、ならびに自治体独自の政策実施に伴う例規整備を定期的に行います。例規改正の主なプロセスは以下の通りです。
- 改正案の作成:主管課が改正原案を作成する
- 法制執務チェック:法規担当が改正案の法令整合・用字用語・構成を審査する
- 新旧対照表の作成:改正前後の条文を2カラムで対比した資料を作成する
- 関係条例・規則との整合確認:改正が他の例規に影響しないかを確認する
- 議会提出・施行:議決を経て施行する
このうち、Claude Codeが支援できる作業は2〜4のステップです。特に「新旧対照表の作成」と「整合確認」は、テキスト比較という性質上、自動化との親和性が高い作業です。
一方で、自治体には民間企業とは異なる情報セキュリティ上の制約があります。総務省「自治体情報システム強靭性向上モデル(三層の対策)」では、LGWAN(総合行政ネットワーク)に接続する系統と、インターネット接続系を分離することが求められています(総務省 「地方公共団体における情報セキュリティポリシーに関するガイドライン」 2024年3月改定)。条例の改正案テキストを外部のクラウドAPIに直接送信することは、多くの自治体のセキュリティポリシー上、許容されないケースがあります。
そのため、本記事で紹介する実装パターンは、オフライン環境またはオンプレミスで動作させることを基本設計とし、外部APIへの送信が必要な場合は自治体の情報システム担当・セキュリティ責任者との事前確認を必須としています。
自治体でのClaude Code活用全般については、自治体×Claude Code:業務支援の5つの実装事例(2026年版)も参考にしてください。
実装の全体設計:3つの機能と情報フロー
本記事で紹介する支援システムは、次の3つの機能で構成されます。
- 差分抽出モジュール:改正前後の例規テキストを比較し、変更箇所を特定する
- 新旧対照表生成モジュール:差分情報をもとに、2カラム形式の新旧対照表(草案)を生成する
- 整合チェック補助モジュール:改正内容が他の条例・規則と参照・引用関係にある箇所を抽出し、確認リストを生成する
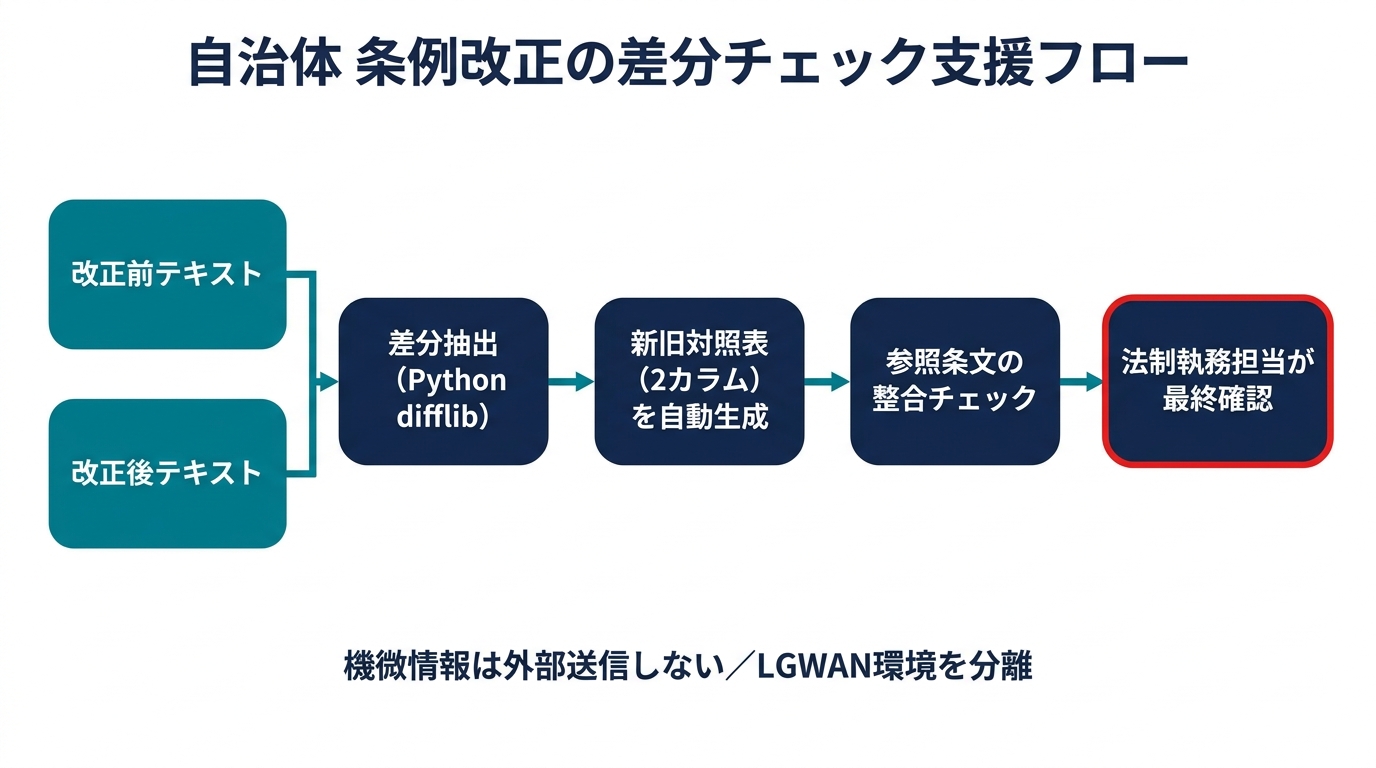
重要なのは、このシステムはあくまで「草案生成と確認補助」に特化し、「条例改正の決定」には関与しない設計であることです。法制執務は高度な専門知識と法的責任を伴う業務であり、AIによる自動化ではなく「自動化できる定型作業の省力化」として位置づけるべきです。
機能1:差分抽出モジュールの実装
Pythonの標準ライブラリdifflibを使えば、外部APIへの送信なしにテキスト差分を抽出できます。以下は、例規テキストの差分をHTML形式で出力する基本実装です。
動作環境:Python 3.10以上、追加ライブラリ不要(difflibは標準ライブラリ)
#!/usr/bin/env python3
"""
ordinance_diff.py
自治体例規テキストの差分をHTMLレポートとして出力するスクリプト
使い方:
python3 ordinance_diff.py --before old_ordinance.txt --after new_ordinance.txt --output diff_report.html
"""
import difflib
import argparse
import pathlib
from datetime import datetime
def load_text(filepath: str) -> list[str]:
"""テキストファイルを行リストとして読み込む"""
with open(filepath, encoding="utf-8") as f:
return f.readlines()
def generate_diff_html(before_lines: list[str], after_lines: list[str],
before_label: str = "改正前", after_label: str = "改正後") -> str:
"""
difflibのHtmlDiffクラスを使って差分HTMLを生成する
charjunkには日本語の記号・句読点を指定し、ノイズを減らす
"""
differ = difflib.HtmlDiff(wrapcolumn=80, charjunk=lambda c: c in "、。・「」『』【】()")
html = differ.make_file(
before_lines,
after_lines,
fromdesc=before_label,
todesc=after_label,
context=True,
numlines=3 # 変更箇所の前後3行を表示
)
return html
def main():
parser = argparse.ArgumentParser(description="例規テキストの差分をHTMLレポートとして出力する")
parser.add_argument("--before", required=True, help="改正前テキストファイルのパス")
parser.add_argument("--after", required=True, help="改正後テキストファイルのパス")
parser.add_argument("--output", default="diff_report.html", help="出力HTMLファイルのパス")
parser.add_argument("--before-label", default="改正前", help="改正前ラベル(デフォルト: 改正前)")
parser.add_argument("--after-label", default="改正後", help="改正後ラベル(デフォルト: 改正後)")
args = parser.parse_args()
before_lines = load_text(args.before)
after_lines = load_text(args.after)
print(f"改正前: {len(before_lines)}行 / 改正後: {len(after_lines)}行")
html_output = generate_diff_html(before_lines, after_lines, args.before_label, args.after_label)
output_path = pathlib.Path(args.output)
output_path.write_text(html_output, encoding="utf-8")
print(f"差分レポートを出力しました: {output_path.resolve()}")
print(f"生成日時: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
if __name__ == "__main__":
main()
実行例:
python3 ordinance_diff.py \
--before "令和5年_○○市環境保全条例.txt" \
--after "令和7年_○○市環境保全条例(改正案).txt" \
--output diff_report.html \
--before-label "令和5年版" \
--after-label "令和7年改正案"
出力されたHTMLをブラウザで開くと、追加された行が緑、削除された行が赤でハイライトされ、変更箇所を一目で確認できます。この段階ではまだClaude Codeは使っていません。差分の「可視化」はPython標準ライブラリだけで完結します。
条番号・条文構造を保持した差分抽出
例規テキストは「第○条」「第○項」「第○号」という条番号構造を持つため、単純なテキスト差分だけでは「どの条のどの項が変わったのか」が把握しにくいケースがあります。以下のように、条番号で分割してから差分を取る実装が有効です。
import re
from dataclasses import dataclass
@dataclass
class Article:
"""条文の構造体"""
number: str # 例: "第3条"
title: str # 例: "(定義)"
body: str # 条文本文
def parse_articles(text: str) -> dict[str, Article]:
"""
例規テキストを条番号ごとに分割する。
条番号パターン: 「第N条」(半角・全角両対応)
"""
pattern = re.compile(r"(第[一二三四五六七八九十百0-90-9]+条)")
parts = pattern.split(text)
articles = {}
i = 1
while i < len(parts) - 1:
number = parts[i]
content = parts[i + 1] if i + 1 < len(parts) else ""
# 条の見出し(括弧書き)を抽出
title_match = re.match(r"\s*(([^)]+))", content)
title = title_match.group(0).strip() if title_match else ""
body = content.strip()
articles[number] = Article(number=number, title=title, body=body)
i += 2
return articles
def diff_by_article(before_text: str, after_text: str) -> list[dict]:
"""
条番号単位で差分を取る。
追加・削除・変更の分類付きで返す。
"""
before_articles = parse_articles(before_text)
after_articles = parse_articles(after_text)
all_numbers = sorted(
set(before_articles.keys()) | set(after_articles.keys()),
key=lambda x: int(re.sub(r"[^0-9]", "", x) or "0")
)
results = []
for num in all_numbers:
if num not in before_articles:
results.append({"number": num, "status": "追加", "before": "", "after": after_articles[num].body})
elif num not in after_articles:
results.append({"number": num, "status": "削除", "before": before_articles[num].body, "after": ""})
elif before_articles[num].body != after_articles[num].body:
results.append({
"number": num,
"status": "変更",
"before": before_articles[num].body,
"after": after_articles[num].body
})
# 変更なしの条は差分リストに含めない
return results
機能2:新旧対照表の自動生成
差分抽出で変更箇所が特定できたら、次は新旧対照表の草案を生成します。ここでClaude Codeが活躍します。
新旧対照表のHTML生成プロンプト
Claude Codeに渡すプロンプトの設計が重要です。以下は、差分データを入力して新旧対照表HTMLを生成するプロンプトのサンプルです。
以下の条例改正差分データをもとに、自治体が使用する形式の新旧対照表(HTML)を生成してください。
【入力データ】
改正名称: ○○市環境保全条例の一部を改正する条例
施行予定日: 令和7年4月1日
変更箇所:
{{ diff_data_json }}
【出力形式の要件】
1. 2カラムの表形式(左列: 改正前、右列: 改正後)
2. 変更箇所は黄色(#FFFDE7)でハイライトする
3. 条番号・見出しは各行の先頭に太字で表示する
4. 表のキャプションに改正名称と施行予定日を含める
5. 文字コードはUTF-8
6. 法令テキスト特有の表記(「〜する場合においては」等)はそのまま維持する
【重要】
- 条文の内容は入力データから忠実に転記し、改変しないこと
- 不明な点があれば質問してから作業を開始すること
- 仮定した点がある場合は、必ず「仮定」と明記すること
このプロンプトを使ったPythonスクリプトの実装例:
import anthropic
import json
def generate_shinkyuu_table(diff_results: list[dict], meta: dict) -> str:
"""
Claude APIを使って新旧対照表HTMLを生成する。
注意: この関数はClaude APIへの接続が必要。
自治体のセキュリティポリシーに従い、使用可否を事前に確認すること。
外部接続が認められない環境では、この関数をオフライン版に差し替えること。
"""
client = anthropic.Anthropic()
diff_json = json.dumps(diff_results, ensure_ascii=False, indent=2)
prompt = f"""以下の条例改正差分データをもとに、自治体が使用する形式の新旧対照表(HTML)を生成してください。
改正名称: {meta.get('title', '条例の一部を改正する条例')}
施行予定日: {meta.get('effective_date', '(施行日は別途確認)')}
変更箇所:
{diff_json}
出力は完全なHTMLテーブルのみを返してください(余分な説明文は不要)。
不足している情報があれば、最初に質問してから作業を開始してください。
仮定した点は必ず「仮定」と明記してください。"""
message = client.messages.create(
model="claude-opus-4-5",
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
return message.content[0].text
外部API不使用のオフライン版(推奨)
多くの自治体環境ではインターネット接続系とLGWAN接続系が分離されており、条例テキストをクラウドAPIに直接送信することが制限されています。そのような環境向けに、Pythonのみで新旧対照表HTMLを生成するオフライン実装も用意しておくべきです。
def generate_shinkyuu_table_offline(diff_results: list[dict], meta: dict) -> str:
"""
外部APIを使わずにPythonのみで新旧対照表HTMLを生成する。
自治体のLGWAN環境など、インターネット接続が制限された環境向け。
"""
title = meta.get("title", "条例の一部を改正する条例")
effective_date = meta.get("effective_date", "(別途確認)")
rows = ""
for item in diff_results:
status_color = {
"追加": "#E8F5E9",
"削除": "#FFEBEE",
"変更": "#FFFDE7"
}.get(item["status"], "#FFFFFF")
before_cell = item.get("before", "(新設)").replace("\n", "
") or "(新設)"
after_cell = item.get("after", "(削除)").replace("\n", "
") or "(削除)"
rows += f"""
{item['number']}
({item['status']})
{before_cell}
{after_cell}
"""
html = f"""
新旧対照表 - {title}
{title}
施行予定日: {effective_date} / 生成日: {__import__('datetime').datetime.now().strftime('%Y年%m月%d日')}
条番号
改正前
改正後
{rows}
※本新旧対照表は自動生成された草案です。必ず法制執務担当者が内容を確認・修正してから正式文書として使用してください。
"""
return html
機能3:参照条文の整合チェック補助
条例改正で特に見落としが生じやすいのが、「改正した条文が他の条例・規則から参照されている」ケースです。たとえば「第○条第○項」という引用が他の例規に存在する場合、改正によって条番号がずれると引用関係が壊れます。
以下のスクリプトは、変更が生じた条番号リストをもとに、例規集全体から参照箇所を洗い出す実装です。
import re
from pathlib import Path
def find_references(changed_articles: list[str], ordinance_dir: str) -> dict[str, list[dict]]:
"""
変更対象の条番号が、例規集のどのファイルで参照されているかを検索する。
Args:
changed_articles: 変更された条番号リスト(例: ["第3条", "第5条", "第7条第2項"])
ordinance_dir: 例規テキストファイルが格納されたディレクトリのパス
Returns:
{条番号: [{ファイル名, 行番号, 行内容}]} の辞書
"""
ordinance_path = Path(ordinance_dir)
results = {num: [] for num in changed_articles}
for txt_file in ordinance_path.glob("**/*.txt"):
try:
lines = txt_file.read_text(encoding="utf-8").splitlines()
except UnicodeDecodeError:
lines = txt_file.read_text(encoding="cp932").splitlines()
for lineno, line in enumerate(lines, start=1):
for article_num in changed_articles:
if article_num in line:
results[article_num].append({
"file": str(txt_file.name),
"line": lineno,
"content": line.strip()
})
return results
def format_reference_report(references: dict[str, list[dict]]) -> str:
"""参照箇所レポートをMarkdown形式でフォーマットする"""
lines = ["# 参照箇所確認リスト", "", "改正対象条文を参照している箇所の一覧です。",
"各箇所について、改正後も引用関係が正しく維持されているか確認してください。", ""]
has_reference = False
for article_num, refs in references.items():
if refs:
has_reference = True
lines.append(f"## {article_num} を参照している箇所 ({len(refs)}件)")
for ref in refs:
lines.append(f"- **{ref['file']}** 第{ref['line']}行: `{ref['content']}`")
lines.append("")
if not has_reference:
lines.append("他の例規からの参照箇所は見つかりませんでした。")
lines.append("---")
lines.append("*このリストは自動生成されたものです。必ず法制執務担当者が確認してください。*")
return "\n".join(lines)
Claude Codeへのプロンプト設計:上位法令との矛盾洗い出し補助
改正案テキストと上位法令(国の法律・政令・省令等)のテキストを並べてClaude Codeに分析させることで、整合チェックの補助が可能です。以下は、その際に使用するプロンプトのサンプルです。
以下の条例改正案と、根拠となる上位法令の関連条文を比較してください。
【条例改正案(関連部分)】
{{ local_ordinance_text }}
【根拠法令(国の○○法 第△△条)】
{{ national_law_text }}
以下の観点から確認してください:
1. 条例の規定が国の法令の委任範囲を超えていないか
2. 用語・定義の整合性(条例で使用している用語が国の法令と異なっていないか)
3. 義務・禁止規定の強度(国の法令と矛盾・競合していないか)
4. 施行日・経過措置の整合性
【注意事項】
- 矛盾・不整合の可能性がある箇所は「要確認」として列挙してください
- 「問題なし」と断定することは避け、「確認不要と思われる」という表現にとどめてください
- 法的判断は担当弁護士・法制執務担当者が行うものであり、このチェックは補助的なものです
- 不明な点があれば質問してから作業を開始してください
- 仮定した点は必ず「仮定」と明記してください
このプロンプト設計のポイントは、Claude Codeに「法的判断」を求めるのではなく「要確認箇所のリストアップ」を求めている点です。AIが「問題ない」と断言してしまうと、法制執務担当が確認を省略するリスクがあります。あくまでチェックリストの素材を提供するツールとして位置づけることが重要です。
セキュリティ設計:自治体の情報ポリシーに準拠するための考慮点
自治体でClaude Codeを活用する際には、以下の情報セキュリティ上の考慮点を必ず確認してください。
三層の対策(総務省ガイドライン)との整合
総務省の自治体情報セキュリティガイドライン(最新版は総務省サイトで確認)では、以下の3つのネットワーク分離が基本とされています:
- マイナンバー利用事務系:個人番号・特定個人情報を扱う。インターネット接続不可
- LGWAN接続系:自治体間通信・国との通信。外部クラウドへの直接接続は原則不可
- インターネット接続系:一般的なインターネット通信。クラウドサービス利用可
条例テキストはマイナンバーを含まないため、マイナンバー利用事務系には該当しませんが、改正案の内密性(議会提出前の未公開情報)が問題になる場合があります。自治体の情報システム担当・総務課・法規担当が共同でセキュリティ分類を判断するプロセスが必要です。
実装時の具体的な対応方針
| 処理フェーズ | 使用する処理 | 外部API送信の要否 | 推奨対応 |
|---|---|---|---|
| 差分抽出 | Python difflib | 不要 | オフライン処理で完結可能 |
| 新旧対照表生成(オフライン版) | Pythonのみ | 不要 | LGWAN接続系でも使用可能 |
| 新旧対照表生成(AI補助版) | Claude API | 必要 | インターネット接続系でのみ。テキストの機密分類確認後に使用 |
| 参照条文検索 | Pythonのみ | 不要 | オフライン処理で完結可能 |
| 上位法令整合チェック | Claude API | 必要 | 公開済みの国の法令テキストのみを入力する設計が望ましい |
ログと監査証跡
行政業務では「いつ、誰が、何の目的でAIを使ったか」の記録が重要です。以下の簡易ログ機能を実装に追加することを推奨します。
import logging
import hashlib
from datetime import datetime
def setup_audit_log(log_path: str = "ordinance_diff_audit.log"):
"""監査ログのセットアップ"""
logging.basicConfig(
filename=log_path,
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
def log_diff_operation(before_file: str, after_file: str, user: str = "unknown"):
"""差分処理の監査ログを記録する"""
# ファイルのハッシュ値を記録(ファイル名だけでなく内容の識別のため)
def file_hash(path):
with open(path, "rb") as f:
return hashlib.sha256(f.read()).hexdigest()[:16]
logging.info(
f"DIFF_OPERATION | user={user} | "
f"before={before_file}({file_hash(before_file)}) | "
f"after={after_file}({file_hash(after_file)})"
)
想定シナリオ:市の環境条例改正での活用イメージ
事例区分: 想定シナリオ(モデルケース)
以下は、100社以上のAI研修・導入支援の経験をもとに構成した典型的な活用シナリオです。実在の自治体・担当者ではありません。
ある市の法規担当課(仮称)では、国の環境関連法改正を受けて市の環境保全条例を改正する必要が生じました。改正対象は12カ条、参照が必要な関連条例が3本という規模でした。
従来の作業フローでは、担当者が2日かけて手作業で新旧対照表を作成し、関連条例の参照箇所を目視確認していました。本システムを導入した想定シナリオでは、以下の変化が見込まれます。
| 作業項目 | 従来(想定) | AI補助後(想定) | 備考 |
|---|---|---|---|
| 差分抽出・変更箇所の特定 | 約2時間 | 約10分(スクリプト実行+確認) | オフライン処理で完結 |
| 新旧対照表草案の作成 | 約5時間 | 約30分(草案生成+修正) | AI生成の草案を担当者が修正 |
| 関連条例の参照箇所確認 | 約3時間 | 約15分(リスト確認+目視確認) | 見落とし防止が主目的 |
| 法制執務チェック(人間) | 約3時間 | 約3時間 | この工程はAIで代替しない |
重要なのは、「法制執務チェック」の工程はAI補助後も同じ時間をかけていることです。AIはあくまでも「定型的な表作成」「参照箇所の網羅的リストアップ」という人手がかかる部分を省力化するものであり、「法的な正確性の担保」は法制執務担当者の専門的判断に委ねられます。
よくある失敗パターンと回避策
失敗パターン1:AI生成の新旧対照表を無修正で使う
❌ 「AIが生成したから正確なはずだ」として法制執務チェックをスキップする
⭕ AI生成の草案はあくまで「入力テキストの整形」であり、法的正確性を保証するものではない。「草案生成済み → 担当者修正 → 確認完了」の承認フローを必ず維持する
なぜこれが重要か:条例テキストにはOCR読み取りエラーや入力ミスが含まれる可能性があります。AIは入力されたテキストをそのまま処理するため、入力段階のエラーが新旧対照表にそのまま反映されます。最終的な正確性確認は人間の責任です。
失敗パターン2:セキュリティ分類を確認せずにクラウドAPIに送信する
❌ 「テキストデータだから問題ないだろう」としてセキュリティ確認を省略し、改正案テキストを直接クラウドAPIに送信する
⭕ 議会提出前の改正案は「未公開情報」として扱う必要がある場合があります。情報システム担当・総務課・法規担当が共同でセキュリティ分類を確認し、組織のセキュリティポリシーに従った使用判断を行う
なぜこれが重要か:情報漏洩が起きた場合、単なる業務ミスではなく行政情報管理上の問題となる可能性があります。ツールの便利さより、まずセキュリティ確認を先行させることが不可欠です。
失敗パターン3:上位法令との整合チェックをAIに任せきりにする
❌ 「AIが問題なしと言ったから大丈夫」として上位法令との整合確認を省略する
⭕ AIのチェック結果は「要注意箇所のリストアップ」であり、「問題なし」の保証ではない。AIが指摘しなかった箇所についても、担当者が独自に確認する姿勢を維持する
なぜこれが重要か:AIは法解釈の専門家ではありません。特に「委任立法の範囲」「地方自治法との関係」「特別法と一般法の関係」といった法律解釈を要する判断は、法制執務担当者または顧問弁護士が行うべきです。
失敗パターン4:既存の例規管理システムと連携を考えずに独自ツールを構築する
❌ 既存の例規管理システムのフォーマットを無視してツールを開発し、結果的にデータ移行に多大なコストがかかる
⭕ 自治体が導入している例規管理システム(○○例規管理システム等)のデータ出力フォーマット(多くはXMLまたはCSV)に対応した入力処理を最初から設計する
自治体のDX担当者が知っておくべき法制執務AIの現在地
2026年現在、法制執務AIの活用は全国の自治体で模索段階にあります。総務省は「デジタル行財政改革」の中で自治体DXを推進しており、例規管理のデジタル化・AI活用についても調査・研究が進んでいます(総務省 地方公共団体DX推進計画)。
e-Gov法令検索(https://elaws.e-gov.go.jp/)では国の法令をXMLおよびTXT形式でダウンロードできます。上位法令との整合チェックに活用する際は、この公開データを入力として使用することで、「公開情報のみを外部送信する」という設計が可能です。
先進的な取り組みとしては、AIを使った法令解析の研究も進んでいます。ただし、現時点では自治体の本番業務への本格導入事例は限られており、多くはPoC(概念実証)段階です。本記事で紹介した実装パターンも、まずは限定的なユースケースでの検証から始めることを推奨します。
問い合わせ対応でのClaude Code活用については、自治体の問い合わせ振り分けをClaude Codeで自動化するも参考にしてください。
実装ロードマップ:3フェーズでの導入計画
Phase 1(1〜2ヶ月):オフライン差分チェックの試験導入
まず外部API送信を一切使わないオフライン版(difflibベース)の差分チェックツールを特定部署の1案件に適用します。この段階では「AI」という要素はなく、単純なテキスト比較スクリプトです。セキュリティリスクがなく、導入の障壁が低い出発点となります。
Phase 2(3〜4ヶ月):参照条文検索の全例規への適用
Phase 1で信頼を得られたら、参照条文検索機能を全例規ディレクトリに適用します。例規管理システムとの連携(テキストエクスポート形式への対応)もこのフェーズで整備します。改正作業の前に「関連する条番号が他のどの例規で引用されているか」を自動リストアップする仕組みが完成します。
Phase 3(5〜8ヶ月):セキュリティ確認を経たAI補助機能の追加
情報システム担当・セキュリティ責任者との協議を経て、セキュリティポリシーと整合する範囲でClaude APIを活用した新旧対照表草案生成・整合チェック補助を追加します。この段階では「AIが生成したものを担当者が必ず確認する」承認フローを制度として明文化することが重要です。
よくある質問(FAQ)
- Q1. LGWAN環境でもClaude Codeは使えますか?
- A1. 差分抽出や参照条文検索のオフライン機能はLGWAN環境でも使用できます。AI補助機能(Claude API利用)はインターネット接続が必要なため、LGWAN接続系から直接使用することはできません。インターネット接続系の端末での利用、またはオンプレミス型AIの検討が必要です。各自治体の情報セキュリティポリシーに従ってください。
- Q2. どのくらいの技術力が必要ですか?
- A2. 差分抽出のオフライン版はPython標準ライブラリのみを使用しており、Pythonの基礎知識(ファイル読み込み、コマンドライン実行)があれば動かせます。Claude API連携版はAnthropicのSDKセットアップが必要ですが、公式ドキュメントに従えば非エンジニアでも導入できます。GovTech支援ベンダーに依頼する場合は、API連携の設定のみを依頼するという選択肢もあります。
- Q3. 生成された新旧対照表の著作権はどうなりますか?
- A3. 法的な問題は専門家(弁護士)にご確認ください。一般的な理解としては、条例テキストは法令として著作権法の適用範囲外(第13条)ですが、新旧対照表の構成・編集に係る部分については別途の検討が必要な場合があります。各自治体の法規担当および法務顧問に相談することを推奨します。
- Q4. AIが生成した新旧対照表に誤りがあった場合の責任は誰にありますか?
- A4. 最終的な成果物に誤りがあった場合の責任は、内容を確認・承認した法制執務担当者および組織にあります。AIはツールであり、ツールの出力の正確性を保証する責任は使用者にあります。このため、本記事でも一貫して「AI生成の草案は必ず担当者が確認する」というフローを強調しています。
- Q5. 市販の例規管理システムとの連携はできますか?
- A5. 多くの例規管理システムはテキスト形式またはXML形式でデータをエクスポートする機能を持っています。本記事のスクリプトはテキスト形式を基本としており、XML形式のエクスポートには
xml.etree.ElementTree(Python標準)を使ったパーサーの追加が必要です。具体的な連携仕様は各システムベンダーに確認してください。
まとめ:今日から始める3つのアクション
本記事では、自治体の条例改正差分チェックと新旧対照表作成をClaude Codeで支援する実装パターンを解説しました。
- 今日やること:本記事の
ordinance_diff.pyをローカル環境で動かし、過去の改正案テキスト2件で差分HTMLレポートを1件生成してみる(外部API不使用・セキュリティリスクなし) - 今週中:情報システム担当・法規担当・総務課の3者で「AI活用のセキュリティ分類」について1時間の検討会を設定する
- 今月中:Phase 1(オフライン差分チェック試験導入)の計画書を作成し、来期の例規改正案件への適用スケジュールを立てる
自治体の法制執務は、精度と法的責任の重さから「AI化しにくい業務」と思われがちです。しかし「定型的な表作成」「網羅的な参照箇所の洗い出し」という部分は、技術的には比較的シンプルに自動化できます。
重要なのは、「AIが判断する」のではなく「AIが準備し、人間が判断する」という役割分担を明確にした設計です。この原則を守ることで、自治体特有のセキュリティ・信頼性要件と、AI活用による省力化の両立が可能になります。
参考・出典
- 総務省「地方公共団体における情報セキュリティポリシーに関するガイドライン」(2024年3月改定)(参照日: 2026-05-31)
- e-Gov法令検索(デジタル庁)(参照日: 2026-05-31)
- 総務省「地方公共団体におけるDX推進の関連資料」(参照日: 2026-05-31)
- Anthropic Claude公式ドキュメント(参照日: 2026-05-31)


