
結論:建設業の積算・見積書作成は、Claude Codeを使って「PDF数量拾い出し→単価マスタ照合→見積明細ドラフト生成→Excel出力」の4工程を半自動化できます。ただし単価の最終判断と過大・過少見積の確認は必ず積算担当者が行う設計が前提です。
- 要点1:仕様書・数量計算書のPDFからpdfplumberでテキスト抽出し、Claude Codeで工種・数量・単位を構造化するプロンプト設計が最初のボトルネック
- 要点2:過去見積DB(CSV/Google Sheets)を単価マスタとして整備しておくことで、Claude Codeが工種コードを照合してドラフト単価を提案できるようになる
- 要点3:標準見積書様式に基づく記載事項チェック補助もプロンプト設計で組み込めるが、法的判断は人間必須
対象読者:建設会社の積算担当・情報システム担当・現場兼務エンジニア・建設DX推進担当
今日やること:手元の仕様書PDFをpdfplumberで開き、テキスト抽出が正常にできるか確認する(後述の確認スクリプトをそのまま実行できます)
「積算って結局、熟練者の手作業が8割なんです」
建設会社の情報システム担当の方から、こんな話を聞いたことがあります。図面や仕様書を読み込んで工種を拾い出し、過去の実績や歩掛を参照しながら単価を組み立て、諸経費を加算して最終的な見積書を仕上げる——この工程は確かに職人技の側面があります。
ただ正直なところ、「熟練者の手作業」の中には、テキストを読んで転記する・過去ファイルを検索して数字を拾う・Excelに項目を打ち込む、といった部分が相当割合含まれています。このルーティン部分であれば、Claude Codeで補助できる余地が十分あります。
本記事では、建設業の積算・見積書作成を「完全自動化する」のではなく「ドラフト生成と転記作業を半自動化して積算担当者が判断に集中できる環境を作る」実装パターンを解説します。コード例はそのまま試せる形で記載しており、建設DXの第一歩として使える内容にしています。
なお、本記事の実装例は想定シナリオ(モデルケース)です。実際の運用では自社の建設業法対応・セキュリティポリシー・単価DBの状態に応じた調整が必要です。
建設業の積算・見積書作成で「半自動化できる部分」と「人間が必須の部分」
実装設計の前に、まず切り分けを明確にしておきます。Claude Codeを建設積算に使う時、最大の失敗パターンは「AIに丸投げしようとする」ことです。
Claude Codeで半自動化できる作業
- テキスト抽出と構造化:仕様書・数量計算書PDFのテキストを読み込み、「工種名」「数量」「単位」「施工条件」を項目ごとに整理する
- 単価マスタとの照合:拾い出した工種名を過去見積DBと照合し、候補単価を提案する(複数候補がある場合は選択肢を出す)
- 見積明細ドラフトの生成:数量×単価の計算と、明細行の整理をExcelフォーマットで出力する
- 歩掛・諸経費の計算:直接工事費に対して事前定義した諸経費率を自動計算する
- 記載事項のチェック補助:建設業法上の必須記載項目が含まれているかをリストアップして確認を促す
- 過去見積の検索:「○○工事の類似案件」をキーワードで過去ファイルから検索・参照する
必ず人間が判断・確認する作業
- 単価の最終決定:市況・材料費・労務費の変動を踏まえた単価は積算担当者が最終確認する
- 過大・過少見積のリスク判断:現場条件・工法の特殊性・施工難易度に起因する調整は人間の判断が必須
- 建設業法上の要件確認:建設業法第20条の交付義務と、標準見積書様式の記載事項への最終適合確認
- 図面の読み取りが必要な箇所:CAD図面の数量拾いは現状のテキストベースアプローチでは対応困難
- 協力会社への発注価格:外部に影響する金額は特に慎重な確認が必要
この切り分けを前提に、実装を進めていきます。建設積算ツールの法律的背景として、建設業法第20条(見積書の交付義務)については国土交通省の公式資料(国土交通省: 建設業法令遵守ガイドライン)を参照してください。
Step 1: 仕様書・数量計算書PDFからテキストを抽出する
最初のボトルネックは、PDFからのテキスト抽出精度です。建設業では仕様書・数量計算書・工事内訳書など多様なPDFを扱いますが、すべてが均一な品質で抽出できるわけではありません。
動作環境とインストール
# Python 3.10 以上
# 仮想環境を作成してから実行推奨
python3 -m venv venv
source venv/bin/activate
pip install pdfplumber anthropic openpyxl pandas python-dotenv
PDF抽出の確認スクリプト
まず手元のPDFがpdfplumberで正常に読めるかを確認します。テキストレイヤーが存在するかどうかが、以降の精度を大きく左右します。
#!/usr/bin/env python3
# check_pdf.py — PDFのテキスト抽出可能か確認するスクリプト
import pdfplumber
import sys
def check_pdf(pdf_path: str) -> None:
"""PDFからテキスト抽出を試みてサマリーを表示"""
with pdfplumber.open(pdf_path) as pdf:
print(f"ページ数: {len(pdf.pages)}")
for i, page in enumerate(pdf.pages[:3]): # 最初の3ページだけ確認
text = page.extract_text()
if text:
char_count = len(text.strip())
print(f" Page {i+1}: {char_count}文字 抽出成功")
# 最初の200文字をプレビュー
print(f" プレビュー: {text.strip()[:200]}")
else:
print(f" Page {i+1}: テキスト抽出失敗(スキャン画像の可能性)")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使い方: python check_pdf.py /path/to/spec.pdf")
sys.exit(1)
check_pdf(sys.argv[1])
Claude Codeへの渡し方
テキスト抽出が確認できたら、Claude Codeに構造化を依頼します。CLAUDE.mdに以下を記載しておくことで、毎回の指示が簡潔になります。
# CLAUDE.md — 積算補助プロジェクト設定
## 役割
建設業の積算・見積作成補助エージェント。
PDFから抽出したテキストを構造化し、単価マスタとの照合を支援する。
## 重要ルール
1. 単価は必ず「候補値」として提案する。確定値として出力しない
2. 不明確な工種・数量は「要確認」フラグを立てる
3. 外部APIへのリクエストには最小限の情報のみ含める
4. 単価マスタ(unit_price_master.csv)はローカルファイルのみ参照する
## 出力フォーマット
- 工種: 文字列
- 数量: 数値
- 単位: 文字列(m/m2/m3/t/本/式 等)
- 施工条件: 文字列(特記があれば)
- 要確認フラグ: boolean
Step 2: 抽出テキストから工種・数量を構造化する
テキスト抽出ができたら、次はClaude APIを使って非構造化テキストを構造化データに変換します。これが積算補助の核になる部分です。
#!/usr/bin/env python3
# extract_quantities.py — 仕様書テキストから工種・数量を構造化する
import anthropic
import json
import pdfplumber
from pathlib import Path
from dotenv import load_dotenv
load_dotenv()
def extract_text_from_pdf(pdf_path: str) -> str:
"""PDFから全ページのテキストを結合して返す"""
texts = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
if text:
texts.append(text.strip())
return "\n\n".join(texts)
def structure_quantities(raw_text: str) -> list[dict]:
"""
Claude APIで工種・数量・単位を構造化する
※ APIに送信するテキストは数量計算書部分に限定すること(社内情報の流出防止)
"""
client = anthropic.Anthropic()
prompt = f"""以下は建設工事の数量計算書または仕様書から抽出したテキストです。
工種・数量・単位を構造化してJSON形式で出力してください。
【重要ルール】
- 不明確な数量は「要確認」フラグをtrueにする
- 複数の解釈ができる工種名は「解釈メモ」に記録する
- 捏造・推測をしない。テキストにない情報は出力しない
テキスト:
{raw_text[:3000]} # 最大3000文字に制限(API送信量のコントロール)
出力形式(JSON配列):
[
{{
"工種": "工種名",
"数量": 数値またはnull,
"単位": "単位文字列",
"施工条件": "特記事項",
"要確認": true/false,
"解釈メモ": "不明点があれば記録"
}}
]
"""
message = client.messages.create(
model="claude-opus-4-5",
max_tokens=2048,
messages=[{"role": "user", "content": prompt}]
)
# JSON部分を抽出してパース
response_text = message.content[0].text
# JSONブロックを探す
import re
json_match = re.search(r'\[.*\]', response_text, re.DOTALL)
if json_match:
return json.loads(json_match.group())
return []
if __name__ == "__main__":
import sys
pdf_path = sys.argv[1] if len(sys.argv) > 1 else "spec.pdf"
print(f"PDFからテキスト抽出中: {pdf_path}")
raw_text = extract_text_from_pdf(pdf_path)
print("Claude APIで構造化中...")
quantities = structure_quantities(raw_text)
# 結果を表示
print(f"\n抽出された工種数: {len(quantities)}")
for item in quantities:
flag = "⚠️ 要確認" if item.get("要確認") else "✅"
print(f"{flag} {item['工種']}: {item.get('数量', '?')} {item.get('単位', '')}")
# JSONで保存
output_path = Path(pdf_path).stem + "_quantities.json"
with open(output_path, "w", encoding="utf-8") as f:
json.dump(quantities, f, ensure_ascii=False, indent=2)
print(f"\n結果を保存: {output_path}")
実際に詰まるポイント
このステップで最もよく発生する問題は、テキストが「読み取れているが意味が取れていない」ケースです。建設工事の数量計算書は「土砂掘削 V=1,234m3」のような記号・記法が混在しており、単純なパースでは対応しきれないことがあります。
Claude Codeのターミナルで実際に試してみると、このような指示が有効です:
# Claude Codeのターミナルから直接指示する例
# CLAUDE.mdのあるディレクトリで実行
# 「要確認」フラグが立っている項目だけ確認を促す
claude "quantities.jsonを読んで、要確認フラグがtrueの項目を日本語でリストアップして、
それぞれに対して積算担当者が何を確認すべきかを具体的に書いて"
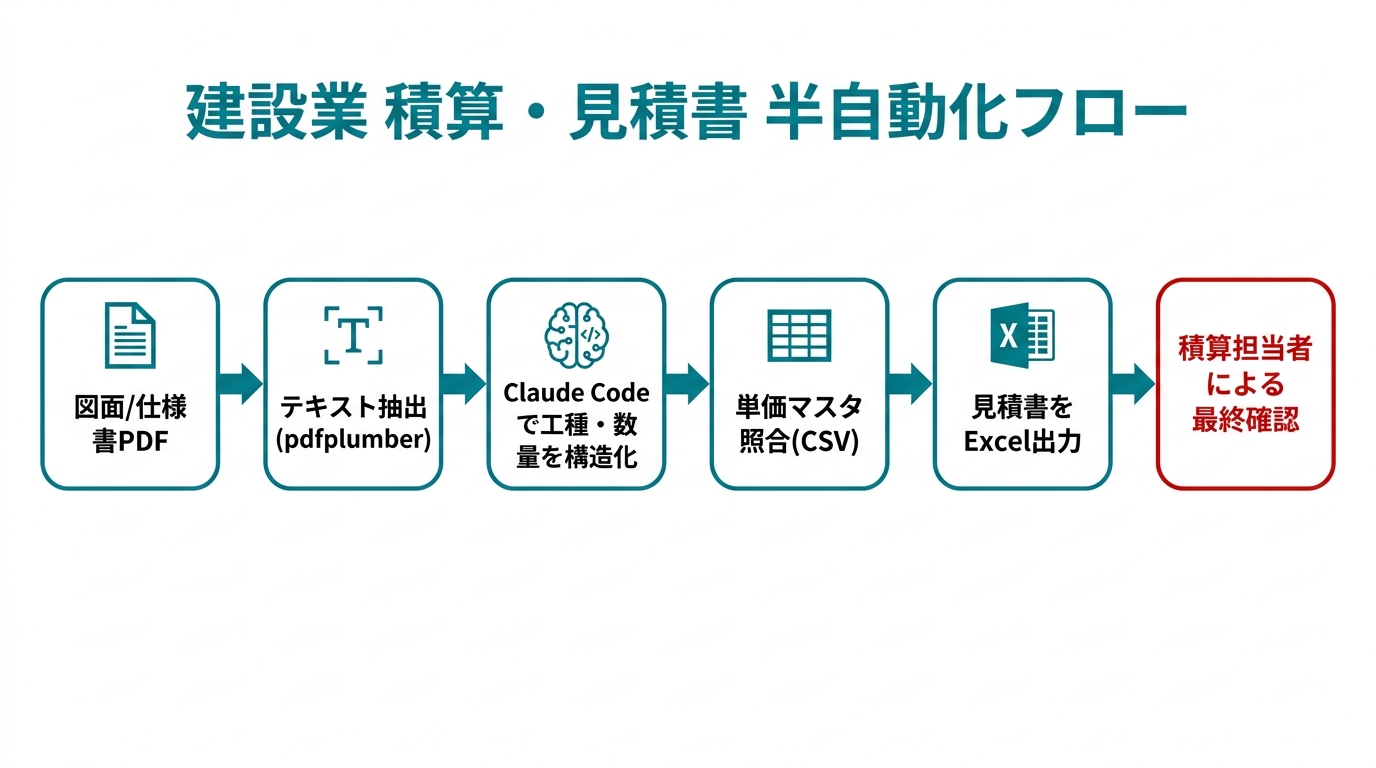
Step 3: 単価マスタCSVを整備して照合する
数量の構造化ができたら、次は単価マスタとの照合です。ここで社内の過去見積データをどう活用するかが、実用性の鍵になります。
単価マスタのCSVフォーマット
最低限このカラムを揃えておけば照合が動きます。既存のExcel見積書から手動で整備するのが現実的な第一歩です。
工種コード,工種名,標準単位,参考単価,単価更新日,地域,備考
EX001,普通土砂掘削,m3,1800,2026-01-15,関東,機械掘削・積込み含む
EX002,岩盤掘削,m3,8500,2026-01-15,関東,発破なし
CF001,コンクリート打設(B=24),m3,35000,2026-03-01,関東,型枠・養生含む
ST001,鉄筋工 SD295A D13,t,180000,2026-03-01,関東,組立含む
AS001,アスファルト舗装 t=5cm,m2,2800,2026-02-01,関東,路盤含まず
単価マスタ照合スクリプト
#!/usr/bin/env python3
# match_unit_prices.py — 数量拾い出し結果と単価マスタを照合する
import anthropic
import json
import csv
import pandas as pd
from pathlib import Path
from dotenv import load_dotenv
load_dotenv()
def load_unit_price_master(csv_path: str) -> list[dict]:
"""単価マスタCSVを読み込む(ローカルファイルのみ)"""
df = pd.read_csv(csv_path, encoding="utf-8")
return df.to_dict(orient="records")
def match_prices_with_claude(
quantities: list[dict],
unit_prices: list[dict],
region: str = "関東"
) -> list[dict]:
"""
Claude APIで工種名を照合し、候補単価を提案する
※ 単価マスタの内容はAPI送信に含める。社内情報として扱い送信範囲を限定すること
"""
client = anthropic.Anthropic()
# 単価マスタをコンパクトに整形(全フィールドを送らない)
master_summary = [
{
"コード": p["工種コード"],
"名称": p["工種名"],
"単位": p["標準単位"],
"参考単価": p["参考単価"],
}
for p in unit_prices
if p.get("地域") == region or not p.get("地域")
]
quantities_text = json.dumps(quantities, ensure_ascii=False, indent=2)
master_text = json.dumps(master_summary, ensure_ascii=False, indent=2)
prompt = f"""建設工事の数量拾い出し結果と単価マスタを照合してください。
【数量拾い出し結果】
{quantities_text}
【単価マスタ({region}・参考値)】
{master_text}
【出力ルール】
- 各数量項目に対して最も近い単価マスタのコードを提案する
- 一致度が低い(60%未満相当)場合は「要確認」フラグをtrueにする
- 単価は「参考値」として扱い、確定値ではないことを明示する
- 単価マスタにない工種は「マスタ外」として別途確認を促す
出力形式(JSON配列):
[
{{
"工種": "入力された工種名",
"数量": 数値,
"単位": "単位",
"照合コード": "マスタのコード or null",
"照合工種名": "マスタの工種名 or null",
"参考単価": 数値 or null,
"参考合計": 数値 or null,
"要確認": true/false,
"確認メモ": "積算担当者への確認事項"
}}
]
"""
message = client.messages.create(
model="claude-opus-4-5",
max_tokens=3000,
messages=[{"role": "user", "content": prompt}]
)
response_text = message.content[0].text
import re
json_match = re.search(r'\[.*\]', response_text, re.DOTALL)
if json_match:
return json.loads(json_match.group())
return []
if __name__ == "__main__":
# 前ステップで生成したquantities.jsonを読み込む
with open("quantities.json", encoding="utf-8") as f:
quantities = json.load(f)
unit_prices = load_unit_price_master("unit_price_master.csv")
print("単価マスタと照合中...")
matched = match_prices_with_claude(quantities, unit_prices)
# 要確認項目を表示
needs_review = [m for m in matched if m.get("要確認")]
if needs_review:
print(f"\n⚠️ 要確認項目: {len(needs_review)}件")
for item in needs_review:
print(f" - {item['工種']}: {item.get('確認メモ', '')}")
# 参考合計を計算(確定値ではない)
total = sum(m.get("参考合計") or 0 for m in matched if not m.get("要確認"))
print(f"\n直接工事費参考合計(要確認除く): ¥{total:,.0f}(参考値・確定前確認必須)")
with open("matched_prices.json", "w", encoding="utf-8") as f:
json.dump(matched, f, ensure_ascii=False, indent=2)
print("照合結果を matched_prices.json に保存")
建設積算における過去見積DBの活用については、建設業日報のClaude Code活用事例も参考になります。同様に現場データを構造化して活用する考え方です。
Step 4: 歩掛・諸経費を計算して見積明細をExcelで出力する
単価照合まで完了したら、いよいよExcel出力です。建設業の見積書には直接工事費に加えて、共通仮設費・現場管理費・一般管理費等の諸経費が乗ります。
諸経費率のコンフィグ管理
# config.py — 諸経費率の設定(社内ルールに基づいて変更する)
# ※ 実際の諸経費率は請負工事の規模・種別・発注者により異なります
# 国土交通省の公共工事設計労務単価・積算基準等を必ず参照してください
EXPENSE_RATES = {
# 工事規模別の参考諸経費率(想定モデル)
"small": { # 500万円未満
"共通仮設費率": 0.10,
"現場管理費率": 0.15,
"一般管理費等率": 0.12,
},
"medium": { # 500万〜3,000万円
"共通仮設費率": 0.09,
"現場管理費率": 0.13,
"一般管理費等率": 0.11,
},
"large": { # 3,000万円以上
"共通仮設費率": 0.08,
"現場管理費率": 0.12,
"一般管理費等率": 0.10,
},
}
def get_expense_tier(direct_cost: float) -> str:
"""直接工事費から諸経費率ティアを判定"""
if direct_cost < 5_000_000:
return "small"
elif direct_cost < 30_000_000:
return "medium"
else:
return "large"
Excel見積書出力スクリプト
#!/usr/bin/env python3
# generate_estimate.py — 見積明細をExcelに出力する
import json
import openpyxl
from openpyxl.styles import Font, Alignment, Border, Side, PatternFill
from openpyxl.utils import get_column_letter
from datetime import date
from config import EXPENSE_RATES, get_expense_tier
def generate_estimate_excel(
matched_prices: list[dict],
project_name: str,
output_path: str = "estimate_draft.xlsx"
) -> None:
"""
単価照合済みデータからExcel見積書ドラフトを生成する
※ 生成されたドラフトは必ず積算担当者が確認・修正してから使用すること
"""
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "見積明細(ドラフト)"
# --- ヘッダー情報 ---
ws["A1"] = "工事見積書(ドラフト — 確認前)"
ws["A1"].font = Font(bold=True, size=14)
ws["A2"] = f"工事名: {project_name}"
ws["A3"] = f"作成日: {date.today().isoformat()}"
ws["A4"] = "※ このドラフトはClaude Codeによる自動生成です。単価・数量は必ず積算担当者が確認してください"
ws["A4"].font = Font(color="FF0000") # 赤字で警告
# --- 列ヘッダー ---
headers = ["工種", "数量", "単位", "参考単価(要確認)", "参考合計(要確認)", "要確認", "確認メモ"]
header_row = 6
for col, header in enumerate(headers, 1):
cell = ws.cell(row=header_row, column=col, value=header)
cell.font = Font(bold=True)
cell.fill = PatternFill(start_color="E0E0E0", end_color="E0E0E0", fill_type="solid")
# --- 明細行 ---
row = header_row + 1
direct_cost_total = 0
for item in matched_prices:
# 要確認項目は黄色でハイライト
fill_color = "FFFF00" if item.get("要確認") else "FFFFFF"
values = [
item.get("工種", ""),
item.get("数量"),
item.get("単位", ""),
item.get("参考単価"),
item.get("参考合計"),
"⚠️ 要確認" if item.get("要確認") else "✅",
item.get("確認メモ", ""),
]
for col, val in enumerate(values, 1):
cell = ws.cell(row=row, column=col, value=val)
cell.fill = PatternFill(start_color=fill_color, end_color=fill_color, fill_type="solid")
if not item.get("要確認") and item.get("参考合計"):
direct_cost_total += item["参考合計"]
row += 1
# --- 諸経費計算 ---
row += 1
ws.cell(row=row, column=1, value="【直接工事費小計(要確認除く参考値)】")
ws.cell(row=row, column=5, value=direct_cost_total)
ws.cell(row=row, column=1).font = Font(bold=True)
row += 1
tier = get_expense_tier(direct_cost_total)
rates = EXPENSE_RATES[tier]
for expense_name, rate in rates.items():
amount = direct_cost_total * rate
ws.cell(row=row, column=1, value=f"{expense_name}({rate*100:.0f}%)")
ws.cell(row=row, column=5, value=amount)
row += 1
# 合計諸経費
total_expense = direct_cost_total * sum(rates.values())
total_amount = direct_cost_total + total_expense
row += 1
ws.cell(row=row, column=1, value="【合計(参考値 — 確認前)】")
ws.cell(row=row, column=5, value=total_amount)
ws.cell(row=row, column=1).font = Font(bold=True, size=12)
ws.cell(row=row, column=5).font = Font(bold=True, size=12, color="FF0000")
# --- 列幅調整 ---
column_widths = [30, 10, 8, 18, 18, 10, 40]
for i, width in enumerate(column_widths, 1):
ws.column_dimensions[get_column_letter(i)].width = width
wb.save(output_path)
print(f"Excel見積書ドラフトを出力: {output_path}")
print("⚠️ 必ず積算担当者が全項目を確認してから使用してください")
if __name__ == "__main__":
with open("matched_prices.json", encoding="utf-8") as f:
matched_prices = json.load(f)
generate_estimate_excel(
matched_prices=matched_prices,
project_name="○○工事",
output_path="estimate_draft.xlsx"
)
Step 5: Claude Codeで建設業法の記載事項チェックを補助する
建設業法第20条は見積書の交付義務と工事費内訳の明示(努力義務)を定めています。記載項目自体は標準見積書様式や国土交通省のガイドラインで示されます。この確認をClaude Codeに補助させることができます。
なお、建設業法の見積書交付義務・記載事項の最新情報は国土交通省の公式ページ(国土交通省 総合政策局 建設業)で必ず確認してください。法的要件への最終確認は人間が行う必要があります。
#!/usr/bin/env python3
# check_legal_requirements.py — 建設業法の記載事項チェック補助
import anthropic
from dotenv import load_dotenv
load_dotenv()
# 標準見積書様式に基づく必須記載事項チェックリスト
# ※ 実際の法的要件は専門家に確認してください
REQUIRED_ITEMS_CHECKLIST = """
建設業法に基づく見積書の確認事項(参考チェックリスト):
1. 工事名称
2. 工事場所
3. 施工する建設工事の概要
4. 工事着手予定時期および工期
5. 請負代金の額(または概算金額)
6. 請負代金の内訳(主な工種・数量・単価)
7. 有効期間
8. 見積書作成者の氏名または名称
※ これはAIによるチェック補助です。法的確認は必ず専門家・自社法務部門に相談してください
"""
def check_estimate_requirements(estimate_content: str) -> str:
"""見積書の記載事項チェックをClaude APIで補助する"""
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-5",
max_tokens=1500,
messages=[{
"role": "user",
"content": f"""以下の見積書ドラフトを確認し、記載事項の不足・不明確な点をリストアップしてください。
{REQUIRED_ITEMS_CHECKLIST}
【見積書内容(テキスト)】
{estimate_content}
出力形式:
- ✅ または ❌ で各項目の有無を表示
- 不足・不明確な項目は具体的に何を補足すべきか記載
- 最後に「積算担当者への確認依頼事項」をまとめる
- AIは法的判断を行いません。最終確認は必ず担当者が行ってください"""
}]
)
return message.content[0].text
# 使い方例
if __name__ == "__main__":
# 見積書ドラフトのテキスト版をここに渡す
sample_content = """
工事名: ○○ビル改修工事
工期: 2026年7月1日〜2026年9月30日
直接工事費合計: ¥12,500,000(参考値)
"""
result = check_estimate_requirements(sample_content)
print(result)
よくある失敗パターン:やりがちなミスと回避策
このシステムを構築・運用するにあたって、実際によく発生する問題とその対処法を整理します。
失敗パターン1: PDFをそのままAPIに投げて機密情報が漏洩する
❌ よくある誤り:pdfplumberで抽出したテキスト全体をそのままClaude APIに送信する
# NG: 全文をそのまま送信(単価・取引先情報・設計金額が含まれる)
response = client.messages.create(
messages=[{"role": "user", "content": f"以下の仕様書を整理してください:\n{full_pdf_text}"}]
)
⭕ 推奨する方法:送信前に不要情報を除外し、数量計算書部分のみに限定する
# OK: 数量計算書セクションのみを抽出してから送信
def extract_quantity_section(full_text: str) -> str:
"""数量計算書セクションのみを抽出する(シンプルなキーワードベース)"""
lines = full_text.split("\n")
in_quantity_section = False
quantity_lines = []
for line in lines:
# 「数量計算書」「数量内訳書」「工事数量」などのキーワードで開始を検出
if any(kw in line for kw in ["数量計算書", "数量内訳書", "工事数量", "数量明細"]):
in_quantity_section = True
# 「金額」「単価」「見積」などが出たら終了(社内単価情報)
elif in_quantity_section and any(kw in line for kw in ["金額", "単価", "見積書", "請負"]):
break
if in_quantity_section:
quantity_lines.append(line)
return "\n".join(quantity_lines)
建設業の図面・仕様書には設計金額・取引先情報・顧客情報が含まれることが多いです。組織のセキュリティポリシーを確認し、情報システム部門・コンプライアンス部門に相談してから外部APIへの送信範囲を決定してください。
失敗パターン2: Claude Codeが出した単価をそのまま見積書に使う
❌ 危険な使い方:照合結果の「参考単価」をレビューなしで見積書に転記する
⭕ 正しい運用:照合結果は「候補値」として扱い、積算担当者が以下を必ず確認する
- 最新の材料費・労務費動向との乖離がないか(特に鉄筋・コンクリート・アスファルトは市況変動大)
- 施工条件(地形・搬入路・施工時期)による補正が必要か
- サブコンからの実際の見積と比較した妥当性
失敗パターン3: テキスト抽出できないPDFで処理を続ける
❌ よくあるエラーへの対処:`extract_text()`がNoneや空文字を返すのに、そのまま処理を続けて誤った構造化結果を生む
# NG: 抽出失敗を検知しない
text = page.extract_text()
quantities = structure_quantities(text) # textがNoneの場合にAPIが誤った結果を返す
# OK: 抽出失敗を検知して早期終了
text = page.extract_text()
if not text or len(text.strip()) < 50:
print(f"警告: Page {page.page_number} のテキスト抽出に失敗しました")
print("手書きスキャンPDFの場合はOCRツール(Tesseract等)が必要です")
print("処理を中断します。手動での数量入力を検討してください")
sys.exit(1)
失敗パターン4: 単価マスタの更新を怠って古い単価で見積もる
⭕ 対策:単価マスタのCSVに更新日カラムを必ず含め、3ヶ月以上古い単価には警告を出す
from datetime import date, timedelta
def check_price_freshness(unit_prices: list[dict], warn_days: int = 90) -> list[str]:
"""古い単価に警告を出す"""
warnings = []
today = date.today()
for price in unit_prices:
updated = date.fromisoformat(price["単価更新日"])
if (today - updated).days > warn_days:
warnings.append(
f"⚠️ {price['工種名']} の単価が{(today - updated).days}日前から更新されていません"
)
return warnings
Permission設計:社内単価DBを守るClaude Codeの設定
Claude Codeはデフォルトではプロジェクトディレクトリ内のファイルを読み書きできます。社内の単価マスタDB・過去見積ファイルを扱う場合は、アクセス範囲を適切に制限する必要があります。
CLAUDE.mdによるpermission設計
# CLAUDE.md — 積算補助エージェントのpermission設計
## アクセス許可するディレクトリ
- ./input/ # 処理対象のPDF
- ./output/ # 生成する見積書ドラフト
- ./unit_price_master.csv # 単価マスタ(読み取りのみ)
## アクセス禁止
- ../ # 上位ディレクトリへのアクセス禁止
- *.secret # 機密ファイルへのアクセス禁止
- ~/Documents/ # 個人ディレクトリへのアクセス禁止
## 外部通信
- Anthropic API のみ許可(単価マスタの外部送信は最小限に)
- データベースへの直接接続禁止(CSVファイル経由のみ)
## 禁止操作
- 見積書の自動送信・メール送信
- 既存見積書ファイルの上書き(新規ドラフトのみ作成可)
- 単価マスタの自動更新
Claude Codeの設定オプションについては公式ドキュメント(Anthropic Claude Code ドキュメント)を参照してください(2026年5月時点)。
Phase別の導入ロードマップ
一度にすべてを自動化しようとすると、現場の混乱と品質低下を招きます。段階的に進めることを強く推奨します。
Phase 1(1〜2ヶ月):PDF抽出と構造化の検証
まず手元の仕様書・数量計算書PDFで、テキスト抽出と工種の構造化精度を検証します。全工種の90%以上が正確に抽出できると確認できてから、次のフェーズに進みます。
- 担当: エンジニア1名 + 積算担当者のレビュー協力
- スコープ: 特定の工種(土工・コンクリート工など限定)のみ
- 成果物: 精度検証レポート + 要対応PDFフォーマットのリスト
Phase 2(3〜4ヶ月):単価マスタ整備と照合機能の実装
過去5年分の見積書から単価マスタを整備します。これが最も工数がかかる工程ですが、一度整備すると継続的な価値を生みます。
- 担当: 積算担当者(マスタ作成)+ エンジニア(スクリプト実装)
- スコープ: 頻出工種100〜200種の単価マスタ作成
- 成果物: 単価マスタCSV + 照合スクリプト
Phase 3(5〜8ヶ月):Excel出力と運用ルールの確立
Excel自動出力と、諸経費計算・法的記載事項チェックを組み込みます。同時に運用ルール(単価の確認フロー・マスタ更新頻度)を整備します。
- 担当: エンジニア + 積算チームリーダー
- スコープ: 社内標準の見積書フォーマットに対応したExcel出力
- 成果物: 積算補助ツール + 運用マニュアル
建設業法・標準見積書との適合ポイント
AI活用での見積書作成は、建設業法上の要件を満たすことが大前提です。以下の点を情シス担当・法務担当と事前に確認してください。
- 建設業法第20条の見積書交付義務:工事の見積書は書面(または電磁的方法)で交付する義務があります。AIドラフトの最終確認後に交付することが前提です(国土交通省「建設業法令遵守ガイドライン」参照)
- 国土交通省の標準見積書:国土交通省では公共工事の標準見積書フォーマットを公開しています(建設工事における見積期間について)。民間工事でも参考になります
- 見積期間のルール:建設業法では発注者からの見積依頼から提出までの期間に下限規定があります(工事の規模により異なる)。AI補助でドラフト作成が早くなっても、法定の見積期間は守る必要があります
建設業DXに関するさらに詳しい実装事例は、設計事務所の図面レビューへのClaude Code活用も参考にしてください。図面情報のAI活用においても同様のpermission設計の考え方が役立ちます。
参考情報・出典
- 国土交通省 建設業 — 建設業法・令・規則等(参照: 2026年5月)
- 建設業法令遵守ガイドライン(第12版)— 国土交通省(参照: 2026年5月)
- Anthropic Claude Code 公式ドキュメント(参照: 2026年5月)
- Anthropic Claude Code — 公式アナウンス(参照: 2026年5月)
まとめ:今日から始める3つのアクション
- 今日やること:手元の仕様書PDFをpdfplumberで開き、テキスト抽出が正常にできるか確認する(本記事の
check_pdf.pyをそのまま使えます) - 今週中:過去5〜10件の見積書から工種名・単価をCSVに書き出して「最小単価マスタ」を作る。完璧を目指さず、まず動くものを作る
- 今月中:単価マスタと
match_unit_prices.pyを使った照合を試し、「要確認」フラグの精度を積算担当者と一緒に評価する
建設積算の「熟練者の手作業」は確かに存在します。ただ、その中の「読んで転記する」「検索して数字を拾う」部分を半自動化するだけで、積算担当者が本当に判断すべき「この工法でこの単価は妥当か」「現場条件を考えると補正が必要か」という思考時間が増えます。
全自動化ではなく「ドラフト生成でスタートラインを上げる」——このアプローチが建設DXの現実的な第一歩です。
あわせて読みたい:建設業の安全管理書類をClaude Codeで効率化


