
結論:Claude Code の Subagents(サブエージェント)は、独立した会話履歴・専用プロンプト・限定ツール権限を持つ専門エージェントを .claude/agents/ に定義し、1つのメッセージ内で複数同時起動することで並列開発を実現する仕組みです。環境依存があるベータ機能の Agent Teams と違い、全環境で安定動作します。
- 要点1:
.claude/agents/<name>.mdに frontmatter(name / description / tools / model)を書くだけで専門エージェントが定義できる - 要点2:1つのプロンプトで複数の Task ツール呼び出しを並べると同時並行で走り、独立タスクの実行時間を大幅に短縮できる
- 要点3:各エージェントは独自コンテキストを持つためトークンを消費する—依存関係・コスト設計・共有状態を意識した設計が必須
対象読者:Claude Code を業務導入済みのエンジニア・PM。複数ファイルの同時調査・並列レビュー・専門役割分担を実装したい方
今日やること:mkdir -p .claude/agents && touch .claude/agents/code-reviewer.md を実行して、最初の専門エージェントを作る
「Claude Code が重いタスクで詰まってしまう」「大きな調査を一つのセッションで回すとコンテキストが膨らんで精度が落ちる」——こういう相談を最近よく受けます。
私自身、この問題に直面したのは、あるSaaSプロダクトの技術負債調査を Claude Code に任せた時でした。30ファイルを超えるレガシーコードのレビューを1つのセッションで回したら、後半になるほど前のファイルのコンテキストが薄れていって、最終的に「このファイルは先ほど確認したファイルと同じパターンです」という的外れな回答が返ってきた。
そこで Subagents を使って「調査エージェント」「セキュリティレビューエージェント」「依存関係マップエージェント」に分けて同時起動したら、同じ作業が圧倒的に精度よく終わりました。本記事ではその実装パターンを全公開します。
1. サブエージェント(Subagents)とは何か
Claude Code のサブエージェントとは、独立した会話履歴・専用システムプロンプト・限定ツール権限を持つ専門エージェントのことです。
通常の Claude Code セッションは「1つの会話コンテキスト」で全てを処理します。一方、サブエージェントは親セッションから Task ツール(または Agent ツール)を通じて呼び出される「子エージェント」として動作します。子エージェントはそれぞれ独立したコンテキストウィンドウを持ち、親セッションとは会話履歴を共有しません。
定義ファイルは .claude/agents/ ディレクトリに Markdown ファイルとして置きます。
.claude/
├── agents/
│ ├── code-reviewer.md # コードレビュー専任
│ ├── researcher.md # 広範調査専任
│ ├── test-runner.md # テスト・品質チェック専任
│ └── security-auditor.md # セキュリティ監査専任
└── CLAUDE.md # プロジェクト共通設定各ファイルの構造は YAML frontmatter + 本文(システムプロンプト)です。
---
name: code-reviewer
description: "コードレビュー専任エージェント。PRのdiffを受け取り、バグ・セキュリティリスク・パフォーマンス問題を指摘する。"
tools:
- Read
- Grep
- Bash(git:*)
- Bash(grep:*)
model: claude-sonnet-4-6
---
あなたは厳格なコードレビュアーです。以下の観点で必ずチェックしてください:
1. **バグ**: ロジックエラー、エッジケース未処理、型エラーの可能性
2. **セキュリティ**: SQLインジェクション、XSS、認証バイパスの可能性
3. **パフォーマンス**: N+1クエリ、不要なループ、メモリリーク
4. **可読性**: 命名規則、コメント、関数の長さ
各指摘は以下の形式で出力してください:
- 重大度: CRITICAL / HIGH / MEDIUM / LOW
- ファイル:行番号
- 説明と修正案この tools フィールドが重要で、エージェントが使えるツールを制限できます。Read と Grep だけに絞れば、そのエージェントはファイルを読むことしかできない。Write も Bash も持たせない—だからコードレビュアーが誤ってファイルを書き換えることがない。これがサブエージェントの強みの一つです。
Agent Teams との違い(重要)
2026年5月時点で、Anthropic は「Agent Teams」という機能も開発中です。ただし、これはベータ機能であり環境依存があります。実際に私のMac環境(Claude Code)でも正常起動しないケースを確認しています。
一方、本記事で解説する .claude/agents/ ベースの Subagents は:
- 全環境で安定動作する
- 設定は Markdown ファイルだけ(ブラウザ画面での操作不要)
- Agent Teams とほぼ同じ「並列実行・役割分担」を実現できる
- Git 管理できるのでチーム共有が楽
Agent Teams が正式リリースされれば使い勝手が増す可能性はありますが、現時点では Subagents が実用上の主役です。本記事も Subagents を中心に解説します。
2. .claude/agents/ の定義ファイルの書き方
定義ファイルは frontmatter + 本文の2部構成です。各フィールドを詳しく見ていきます。
frontmatter フィールド一覧
---
name: エージェント識別子(半角英数字・ハイフン)
description: |
このエージェントを起動すべきシーンの説明。
Claude が自律的に「このタスクにはこのエージェントが適切」と
判断する際にこの description を参照します。
tools:
- Read # ファイル読み込み
- Write # ファイル書き込み
- Edit # ファイル編集
- Bash(git:*) # Git コマンドのみ
- Bash(npm:*) # npm コマンドのみ
- Grep # テキスト検索
- Glob # ファイルパターン検索
- WebFetch # URLフェッチ
model: claude-sonnet-4-6 # または claude-haiku-4-5 等
---tools フィールドに Bash(git:*) のように書くと、Bash ツールの中でも特定コマンドだけを許可できます。セキュリティ観点で「最小権限の原則」を適用できるのが Subagents の設計思想です。
description は重要です。Claude が「どのエージェントを使うべきか」を判断する際にこのフィールドを読みます。「コードを書いて」というあいまいな指示でも、description が的確ならClaude が適切なエージェントを選択します。
実テンプレート集(コピー可)
テンプレート1: researcher(広範調査専任)
---
name: researcher
description: |
大規模調査・情報収集を専任で行うエージェント。
複数ファイルの横断検索、外部URLのフェッチ、
コードベースの全体把握に使う。
「調査して」「どこで使われてる?」「全体を把握して」が起動サイン。
tools:
- Read
- Grep
- Glob
- Bash(find:*)
- Bash(grep:*)
- WebFetch
model: claude-haiku-4-5
---
あなたはコードベース調査の専門家です。以下の調査を行う際は:
1. まず Glob でファイル構造全体を把握する
2. Grep で関連するパターンを横断検索する
3. 見つかった各ファイルを Read して詳細確認する
4. 調査結果は「ファイルパス + 該当箇所 + 理由」の形式でまとめる
調査は徹底的に行い、「見つかりませんでした」という回答をする前に
少なくとも3つの異なる検索アプローチを試みること。テンプレート2: code-reviewer(コードレビュー専任)
---
name: code-reviewer
description: |
コードレビュー専任。PR のdiff・特定ファイル・関数を受け取り、
バグ・セキュリティリスク・パフォーマンス・可読性を審査する。
「レビューして」「問題ない?」「チェックして」が起動サイン。
tools:
- Read
- Grep
- Bash(git:*)
model: claude-sonnet-4-6
---
あなたは Senior Software Engineer として厳格なコードレビューを行います。
## 審査観点(全件確認必須)
### CRITICAL(即ブロック)
- SQLインジェクション・XSS・コマンドインジェクションの可能性
- 認証・認可のバイパス経路
- パスワード・APIキーのハードコード
### HIGH(マージ前に修正)
- NullPointerException・配列範囲外アクセスの可能性
- 無限ループ・デッドロックのリスク
- N+1クエリ・O(n²)以上のアルゴリズム(データ量が多い場合)
### MEDIUM(改善推奨)
- 命名規則の乱れ(camelCase vs snake_case混在等)
- エラーハンドリングの欠如(握りつぶしtry/catch)
- テストカバレッジの空白
### LOW(参考意見)
- マジックナンバーの直書き
- コメントの不足・陳腐化
## 出力形式
```
[CRITICAL] src/auth/login.php:47
問題: ユーザー入力が直接SQLに連結されている
修正: プリペアドステートメントを使用する
修正案: $stmt = $pdo->prepare("SELECT * FROM users WHERE id = ?"); $stmt->execute([$id]);
```テンプレート3: test-runner(テスト・品質チェック専任)
---
name: test-runner
description: |
テスト実行・品質チェック専任エージェント。
既存テストの実行、カバレッジ確認、
新機能に対するテストケース提案を行う。
「テストして」「カバレッジは?」「テスト書いて」が起動サイン。
tools:
- Read
- Write
- Bash(npm:*)
- Bash(python3:*)
- Bash(pytest:*)
- Bash(jest:*)
model: claude-sonnet-4-6
---
あなたはQAエンジニアとして品質保証を担当します。
テスト実行時は必ず:
1. テスト前にカバレッジレポートのベースラインを取る
2. テスト実行・結果の記録
3. 失敗テストがあれば原因を分析して報告
4. カバレッジが80%未満の箇所を特定して追加テストを提案する
新規テストを書く時は、ハッピーパス・エラーパス・エッジケースの3パターンを必ず含めること。テンプレート4: security-auditor(セキュリティ監査専任)
---
name: security-auditor
description: |
セキュリティ監査専任エージェント。
OWASPトップ10・認証・データ保護の観点でコードを審査する。
「セキュリティチェック」「脆弱性ある?」「本番前に確認して」が起動サイン。
tools:
- Read
- Grep
- Bash(grep:*)
- Bash(find:*)
model: claude-sonnet-4-6
---
あなたはセキュリティエンジニアとして OWASP Top 10 を軸に審査します。
## 必須チェックリスト
### A01: アクセス制御の不備
- エンドポイントに認証チェックがあるか
- 水平権限昇格(他ユーザーのリソースへのアクセス)の可能性
### A02: 暗号化の失敗
- パスワードの平文保存・MD5/SHA1使用
- HTTPSでない通信・証明書検証スキップ
### A03: インジェクション
- SQLインジェクション・コマンドインジェクション・XSS
### A07: 認証の失敗
- セッション管理の問題・ブルートフォース対策の欠如
報告は「ファイルパス・行番号・深刻度・具体的な修正方法」で。テンプレート5: doc-writer(ドキュメント生成専任)
---
name: doc-writer
description: |
ドキュメント生成専任エージェント。
関数・クラス・APIのJSDoc/docstring生成、
README更新、変更履歴の作成を行う。
「ドキュメント書いて」「README更新して」「コメント追加して」が起動サイン。
tools:
- Read
- Write
- Edit
- Grep
model: claude-haiku-4-5
---
あなたはテクニカルライターです。コードを読んで正確で簡潔なドキュメントを生成します。
生成するドキュメントは:
- 「何をするか」ではなく「なぜそうするか」を中心に
- パラメータと戻り値は必ず型と説明を含める
- 使用例を1つ以上含める
- 既存のスタイルガイド(JSDoc / NumPy / Google スタイル)に合わせる3. 並列起動の実際——1メッセージで複数エージェントを動かす
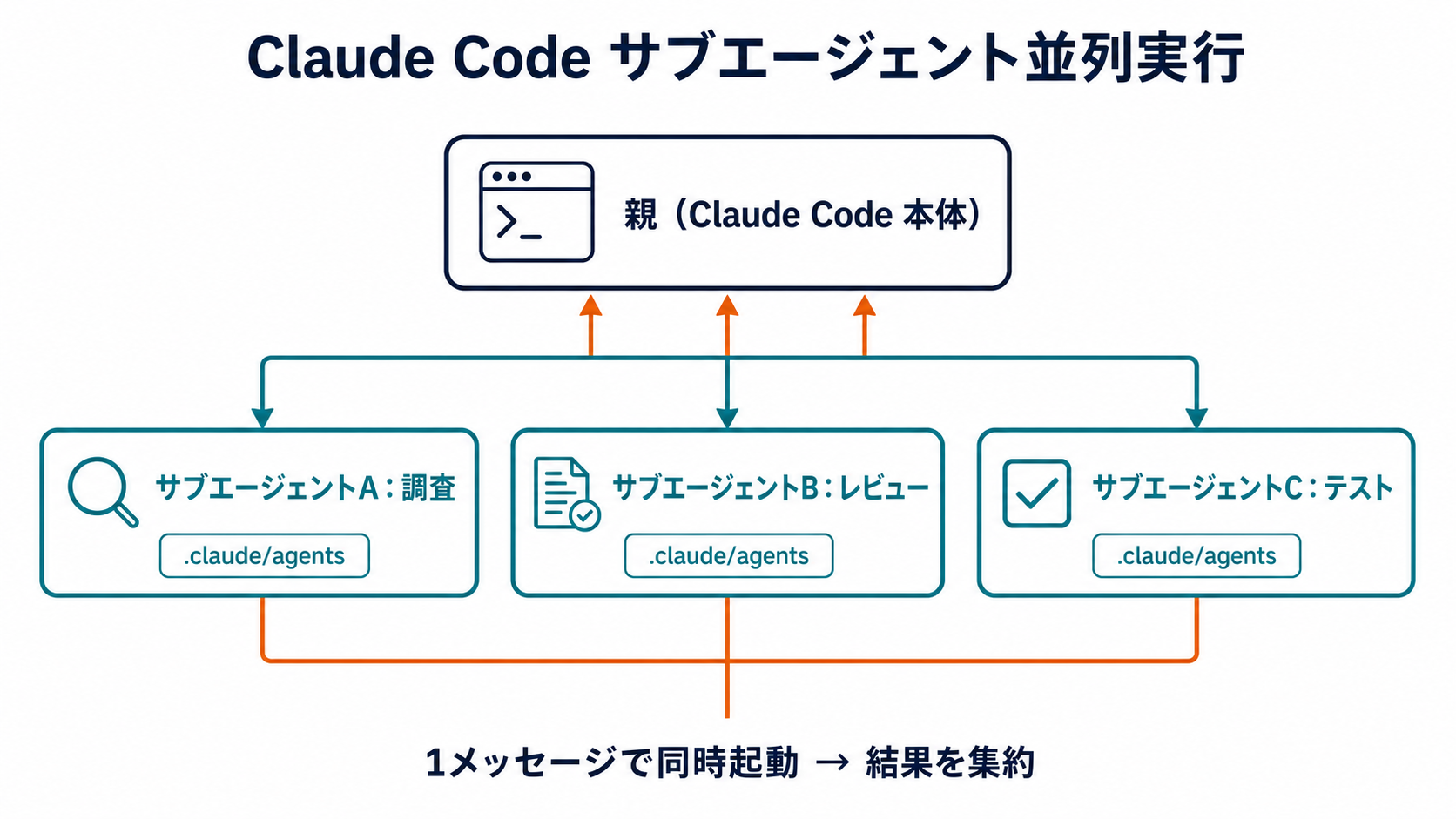
Subagents の最大の強みは並列実行です。1つのプロンプト内で複数のエージェントを呼び出すと、Claude Code はそれらを同時並行で実行します。
並列起動の仕組み
ユーザーから「このPRをレビューして、セキュリティチェックもして、テストが通るか確認して」と指示された場合、Claude Code は以下のように動作します:
親セッション(オーケストレーター)
├─ [並列] code-reviewer エージェント → diff を読んでレビュー
├─ [並列] security-auditor エージェント → セキュリティ観点で審査
└─ [並列] test-runner エージェント → テストを実行・結果を報告3つのエージェントが同時に動き、それぞれの最終メッセージが親セッションに返ってきます。逐次処理なら3倍かかる時間が、独立したタスクなら1倍の時間で終わります。
重要な点として、各エージェントの中間ファイルや中間的なやりとりは親に返ってきません。返ってくるのは各エージェントの「最終的な結論・報告」だけです。そのため、エージェントのシステムプロンプトに「結論を必ず最後に出力してください」と書いておくのが実践上の重要なコツです。
プロンプトでの使い方(実例)
実際に並列起動を誘発するプロンプトの書き方:
## 指示(並列実行)
以下の3つのタスクを同時に実行してください:
タスク1: code-reviewerエージェントで `src/auth/` ディレクトリ全体をレビューし、
CRITICAL と HIGH の問題を列挙してください。
タスク2: security-auditorエージェントで同ディレクトリをOWASP観点で審査し、
認証・認可の問題がないか確認してください。
タスク3: researcherエージェントで `src/auth/` が他のファイルからどう呼ばれているか
依存関係を全て洗い出してください。
3つの結果が揃ったら統合報告を出してください。逐次処理が必要な場合
並列にできないのは前段の出力が次段に必要なケースです。たとえば:
- 「まずコードを書いて(Write エージェント)、次にそのコードをレビューして(code-reviewer エージェント)」 → 順番に依存があるので逐次
- 「ファイルAとファイルBを同時に調査して」 → 独立しているので並列OK
## 判断基準
並列にしてよい ✅
- 複数の独立したファイル・ディレクトリの調査
- 複数の視点からの同一対象のレビュー(コード品質 vs セキュリティ)
- 複数テストスイートの同時実行
逐次にすべき ❌
- 「コード生成 → その結果をレビュー」
- 「設計書作成 → 設計書を読んで実装」
- 「テスト実行 → 失敗したテストを修正」(修正は前結果に依存)4. 役割分担パターン3例——実務で使える構成
パターン1: PR レビュー自動化(コード品質 × セキュリティの二重確認)
チームでよく使うのは「PRを出したら自動で2視点でレビューする」構成です。
CLAUDE.md の設定例:
## PR 提出時の自動エージェント起動ルール
git diff で変更ファイルリストが提示された場合、
以下の2エージェントを並列起動してください:
1. code-reviewerエージェント: バグ・パフォーマンス観点でdiffをレビュー
2. security-auditorエージェント: セキュリティ観点で同じdiffを審査
両方の結果をまとめて以下のフォーマットで報告:
---レビュー結果---
[コード品質] CRITICAL: N件 / HIGH: N件 / MEDIUM: N件 / LOW: N件
[セキュリティ] CRITICAL: N件 / HIGH: N件
マージ可否: OK / REVIEW_NEEDED / BLOCK
---パターン2: 技術負債調査(広範調査の並列分割)
大きなコードベースの調査を担当別に分割して同時進行させる構成です。
## 技術負債調査の指示例
以下を並列で調査してください:
エージェント1 (researcher): `src/api/` ディレクトリの
- 非推奨APIの使用箇所を全て洗い出す
- 結果は「ファイル:行番号 + 使用している非推奨API + 代替案」でまとめる
エージェント2 (researcher): `src/database/` ディレクトリの
- N+1クエリの疑いがあるパターンを検索
- ORMの.all()・.filter()が入れ子になっている箇所を列挙
エージェント3 (security-auditor): プロジェクト全体の
- ハードコードされたシークレット・APIキー・パスワードを検索
- "password", "secret", "api_key", "token" を含む設定ファイルを確認
3エージェントの結果を統合し、優先度付きの技術負債リストを作成してください。パターン3: ドキュメント一括生成(複数ファイル並列ドキュメント化)
新しいモジュールができた時に、全関数のドキュメントを一気に生成する構成です。
## ドキュメント生成の指示例
src/utils/ 配下の以下の3ファイルを並列でドキュメント化してください:
doc-writerエージェント1: src/utils/date.ts
- 全ての export 関数に JSDoc コメントを追加
- パラメータ・戻り値・使用例を含める
doc-writerエージェント2: src/utils/string.ts
- 同上
doc-writerエージェント3: src/utils/validation.ts
- 同上
完了後、各ファイルの変更行数と追加した関数数を報告してください。5. Agent Teams との違い——正直に書く
Anthropic が開発中の「Agent Teams」という機能があります。UIからチームを組んで複数エージェントを管理できる設計で、将来的には強力な機能になる可能性があります。
ただし、2026年5月時点では:
- ベータ機能・実験的——正式リリースではない
- 環境依存——動作しない環境がある(筆者のMac環境での検証でも正常起動しないケースを確認)
- 設定がUI依存——コードベースにテキストファイルで設定を管理できない
一方、.claude/agents/ ベースの Subagents は:
| 比較軸 | Subagents(.claude/agents/) |
Agent Teams(ベータ) |
|---|---|---|
| 安定性 | ✅ 全環境で安定 | ⚠️ 環境依存・ベータ |
| 設定管理 | ✅ Markdown ファイル(Git管理可) | ⚠️ UI操作 |
| チーム共有 | ✅ リポジトリに含めるだけ | ⚠️ 設定共有の仕組みが不明確 |
| ツール制限 | ✅ frontmatter で細かく制御 | ⚠️ 仕様が変動中 |
| 並列実行 | ✅ 1メッセージ内で自然に並列化 | ✅(動いた環境では可能) |
Agent Teams が正式リリースされて安定したら、それはそれで使える選択肢になるでしょう。ただし今の段階で「Agent Teams を使うべき」とは言えません。現在の実用解は Subagentsです。
6. 並列実行の落とし穴——実際にハマったパターン4つ
❌ 落とし穴1: 認証状態を共有するツールの並列起動
これは実際に痛い目を見たパターンです。
何が起きたか:画像生成スクリプト(外部APIを使用、認証トークンをファイルに保存して管理)を複数のエージェントから同時に呼び出した。3つのエージェントが「認証トークンのリフレッシュ → 保存 → API呼び出し」を同時にやろうとしたところ、トークンファイルへの同時書き込みで競合が発生。認証が全て失敗した上、一部のプロセスが無言でハング → 10分後にタイムアウトで失敗しました。
❌ NG: 認証状態を共有するスクリプトを複数エージェントから同時起動
agent_1: codex_imagegen.sh --prompt "..." → 認証リフレッシュ中...
agent_2: codex_imagegen.sh --prompt "..." → 認証リフレッシュ中...(競合!)
agent_3: codex_imagegen.sh --prompt "..." → 認証リフレッシュ中...(競合!)
→ 全エージェントがハングしてタイムアウト
⭕ OK: 認証状態を共有するスクリプトは必ず逐次実行
逐次: 1枚生成 → 完了確認 → 2枚目生成 → 完了確認 → ...ルール:外部の認証状態・ファイルロック・データベース接続プールを共有するツールは並列起動しない。「本当に独立しているか」を起動前に確認する。
❌ 落とし穴2: 依存タスクを並列にして整合性が壊れる
❌ NG: 依存関係を無視した並列化
agent_1: src/models/user.ts を新しいスキーマに合わせて修正
agent_2: src/services/user.service.ts を同じく修正(agent_1の変更結果に依存)
→ agent_2 が agent_1 の変更を知らないまま修正
→ 型エラー・整合性の崩壊
⭕ OK: 依存がある場合は逐次
Step1: agent_1 が src/models/user.ts を修正・完了
Step2: 完了後に agent_2 が更新済み user.ts を参照して service を修正❌ 落とし穴3: コンテキスト肥大によるトークンの過剰消費
並列起動は便利ですが、各エージェントが独自コンテキストを持つということは、エージェント数 × コンテキスト分のトークンが消費されるということです。
❌ NG: 不必要に細かく分割して大量起動
「各ファイルに1つエージェントを割り当てて、200ファイルを並列調査」
→ 200コンテキスト × 数万トークン = 莫大なコスト + API制限に到達
⭕ OK: ディレクトリ単位で分割
「src/api/ 担当エージェント」「src/database/ 担当エージェント」の2つに分ける
→ 各エージェントが担当範囲を自律的に調査、コストも現実的目安として、並列エージェントは3〜8個程度が実用的な上限です(タスクの規模・トークン予算による)。
❌ 落とし穴4: 最終報告の形式が揃わない
❌ NG: 出力形式を指定しないまま並列起動
agent_1 の出力: 「バグが3件見つかりました。詳細は...」(文章)
agent_2 の出力: 「| ファイル | 重大度 | 内容 |」(Markdown表)
agent_3 の出力: 「security_issues = [...]」(JSON)
→ 親セッションが統合しにくい
⭕ OK: 全エージェントの出力形式を統一する(システムプロンプト内に明記)
「報告は必ず以下のJSON形式で出力してください:
{"severity":"CRITICAL","file":"src/...", "line":42, "description":"..."}」7. コスト設計——モデル選定でコストを最適化する
Subagents を使うと各エージェントがトークンを消費するため、モデル選定によるコスト最適化が重要になります。
エージェント別のモデル推奨
| エージェント種類 | 推奨モデル | 理由 |
|---|---|---|
| researcher(調査・収集) | claude-haiku-4-5 |
情報収集は推論能力よりスピードとコストが重要 |
| doc-writer(ドキュメント生成) | claude-haiku-4-5 |
定型的な文書生成は Haiku で十分 |
| code-reviewer(コードレビュー) | claude-sonnet-4-6 |
ロジックエラーの検出には推論能力が必要 |
| security-auditor(セキュリティ審査) | claude-sonnet-4-6 |
脆弱性のパターン認識は精度優先 |
| アーキテクチャ設計・オーケストレーター | claude-opus-4-7 |
複雑な判断・統合には Opus |
frontmatter の model フィールドで各エージェントのモデルを個別に指定できるのが Subagents の強みです。「調査は安いモデルで、最終判断は賢いモデルで」という階層構造が作れます。
コスト見積もりのチェック観点
コスト ≈ エージェント数 × 各エージェントが読むファイルの合計トークン × モデル単価
例: 3エージェント × 平均10,000トークン × Sonnet単価
→ 単独セッション比で約3倍のコスト
ただし: 時間は1/3になる → スピードとコストのトレードオフ時間が重要な場面(CI/CDパイプライン・緊急修正)では並列を使い、コストを節約したい定期バッチ処理では逐次にする、という使い分けが実用的です。
8. CLAUDE.md との連携——エージェントを自動起動させる
Subagents の最大の活用法は、CLAUDE.md に「特定のシーンでは自動的にエージェントを起動する」ルールを書くことです。
## CLAUDE.md のエージェント自動起動設定例
## コードレビュールール
新しいファイルを Write・Edit した後は、
code-reviewerエージェントを自動起動してください。
CRITICAL または HIGH の問題があれば、修正提案を出してから
「レビューが完了しました」と報告してください。
## PRレビュールール
git diff の出力を受け取ったら:
1. code-reviewerエージェントとsecurity-auditorエージェントを並列起動
2. 両方の結果をまとめて「マージ可否」を判定して報告
## 技術調査ルール
「全体を調べて」「どこで使われている」という指示を受けたら
researcherエージェントを起動してください。
自分で直接 Grep・Glob を使わず、専門エージェントに委任すること。こうしておくと、「ファイルを書いた → 自動でレビュー → CRITICALがあれば修正」というループが人間の介入なしに回ります。
Claude Code の開発ワークフロー全体については、SaaS インシデント対応を Claude Code で5ステップ自動化した事例も参照してください。実際のプロジェクトでどうエージェントを組み合わせるかのヒントになります。
9. FAQ
- Q1:
.claude/agents/に置いたファイルはチームメンバー全員に有効ですか? - はい。
.claude/agents/ディレクトリはプロジェクトのリポジトリに含めてコミットできます。git pull すれば全員が同じエージェント定義を使えます。これが「チーム共通のAIワークフロー」として機能します。 - Q2: エージェントに与えるツール権限の考え方は?
- 最小権限の原則を適用してください。「このエージェントが本当に必要なツールだけ」に絞ります。researcher エージェントに Write 権限を与えると、調査エージェントが誤ってファイルを書き換えるリスクが生まれます。Read / Grep / Bash の特定コマンドのみ—これが基本です。
- Q3: サブエージェントと親セッションはファイルを共有できますか?
- ファイルシステムは共有しています。エージェントが特定のファイルに書き込めば、親セッションや他のエージェントもそのファイルを Read で読めます。「エージェント間の通信手段」として中間ファイルを使うパターンが有効です。ただし同時書き込みの競合には注意してください。
- Q4: 並列起動したエージェントが失敗した場合はどうなりますか?
- 失敗したエージェントのエラーが親セッションに返ってきます。他の並列エージェントへの影響はありません(独立して動いているため)。エラーハンドリングのロジックは親セッションのプロンプト(CLAUDE.md)に書いておくのが実用的です。
- Q5: Agent Teams と Subagents は将来的に統合されますか?
- Anthropic の公式発表(2026年5月時点)では明確なロードマップは示されていません。現時点では Subagents が実用上の正解です。Agent Teams が安定したら移行を検討するという判断で問題ないと思います。(参照:Anthropic Claude Code 公式)
- Q6: エージェントを使うとコストはどれくらい増えますか?
- エージェント数に比例して増加します。3エージェント並列 ≈ 単独セッションの3倍のトークン消費が目安です。ただし調査エージェントに
claude-haiku-4-5を使うなどモデルを使い分けることで、コストを抑えながら精度を維持できます。
10. まとめ——今日から始める3つのアクション
サブエージェントを使った並列開発は、慣れるまで少し設計の考え方が変わります。でも、一度動き出すとコードレビュー・セキュリティ監査・技術負債調査が劇的に効率化されます。
- 今日やること:
mkdir -p .claude/agentsを実行して、上記テンプレート1(researcher)を.claude/agents/researcher.mdとして保存する。「このプロジェクトのデータベース接続はどこで行われているか全部調べて」と Claude Code に聞いてみる - 今週中:code-reviewer エージェントを追加して、次にコードを書いた後に「さっきのコードを code-reviewer エージェントでレビューして」と試す。CRITICAL が出たら修正して、エージェントが何を検出したか確認する
- 今月中:チームリポジトリに
.claude/agents/をコミットして、チームメンバー全員がエージェント定義を共有する。CLAUDE.md にエージェント自動起動ルールを書いて、「ファイルを書いたら自動でレビュー」を設定する
MCP(Model Context Protocol)との組み合わせで、サブエージェントが外部ツール・データベース・APIにアクセスする構成も作れます。その実装については、Claude Code × MCP 実践活用ガイドもあわせて参照ください。
また、Codex CLI との使い分け・比較については Codex CLI vs Claude Code 徹底比較 も参考になります。
参考・出典
- Claude Code 公式ドキュメント — Anthropic(参照日: 2026-05-30)
- Claude Code のご紹介 — Anthropic News(参照日: 2026-05-30)
- Building effective agents — Anthropic Research(参照日: 2026-05-30)


